Однофакторный дисперсионный анализ для несвязных выборок

Основываясь на сделанных предположениях, можно оценить ожидаемое значение статистик MSerror и MStreatment. Но для этого необходимо сделать еще одно предположение. Оно будет состоять в том, что независимая переменная фиксирована экспериментатором, т. е. в эксперименте использованы все ее возможные значения, или уровни. Зависимая переменная случайна в том смысле, что реально полученные… Читать ещё >
Однофакторный дисперсионный анализ для несвязных выборок (реферат, курсовая, диплом, контрольная)
Дисперсионный анализ относится к параметрическим методам. Это значит, что он основывается на некоторых теоретических предположениях о характере распределения статистических параметров, таких как математическое ожидание и дисперсия. Различные модели дисперсионного анализа основываются на различных теоретических допущениях, которые принято называть структурными моделями. Прежде чем воспользоваться той или иной разновидностью дисперсионного анализа, необходимо выяснить, в какой степени допущения ее структурной модели соответствуют полученным в эксперименте данным и тому экспериментальному плану, в рамках которого они были собраны.
Если говорить о конкретных экспериментальных данных, то здесь следует сначала отметить, что допущения классической разновидности дисперсионного анализа, разработанного в начале XX в. Р. Фишером, как правило, слишком строги для психологического исследования и далеко не всегда выполняются. Возможно, именно поэтому появилось уже довольно расхожее суждение о том, что параметрические методы, и в частности дисперсионный анализ, непригодны для использования в психологии. К счастью, это не совсем так. Дело в том, что отклонения эмпирических данных от этих строгих теоретических допущений не фатальны даже тогда, когда они становятся весьма значительными. Поэтому в большинстве случаев ими можно смело пренебречь. Наиболее серьезные ограничения дисперсионного анализа относительно структуры и природы экспериментальных данных касаются лишь так называемых планов с повторными измерениями (то, что по-английски принято обозначать как repeated measure), столь широко распространенных в психологии. Они будут рассмотрены в следующих главах. Как правило, такими ограничениями пренебрегать не стоит. В этих случаях желательно перепроверить данные, осуществить специальные коррекционные процедуры, касающиеся изменения самой структуры данных, или даже подумать об изменении экспериментального плана.
Надо отметить, что в настоящее время практически для каждой разновидности экспериментального плана существует своя структурная модель, в том числе для однофакторного плана с несвязными выборками. Это самая простая структурная модель дисперсионного анализа. Рассмотрим основные ее предположения.
Структурная модель
Структурная модель однофакторного дисперсионного анализа для несвязных выборок основывается на нескольких теоретических предположениях. Одни из этих предположений не влекут никаких последствий для экспериментатора, другие — побуждают его к определенным действиям по сравнению выборочных данных с предположениями структурной модели.
Первое предположение однофакторного дисперсионного анализа состоит в том, что всякое конкретное значение зависимой переменной, полученное в эксперименте, состоит из нескольких аддитивных частей. Наглядно это может быть представлено следующим соотношением:
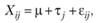
где Xij — значение зависимой переменной для i-го испытуемого в j-й группе;? — популяционная средняя (математическое ожидание зависимой переменной вне какого-либо экспериментального воздействия); ?j — эффект независимой переменной на j-м уровне; ?ij — случайная экспериментальная ошибка.
Мы видим, что значение зависимой переменной в дисперсионном анализе (ANOVA) представляется в виде линейной комбинации аддитивных компонентов. Поэтому данный метод относят к классу методов, которые обозначают как общие линейные модели (GLM). Это наиболее распространенный в психологических исследованиях класс методов математической статистики. Помимо дисперсионного анализа к общим линейным моделям относят регрессионный и факторный анализ. Эти методы обсуждаются в следующих главах.
Возвращаясь к линейной модели однофакторного дисперсионного анализа для несвязных выборок, отметим, что популяционная средняя не зависит ни от испытуемого, ни от уровня независимой переменной. Она всегда постоянна. Поэтому ее дисперсия всегда равна нулю.
Далее заметим, что, поскольку значение? j внутри экспериментальной группы постоянно, внутригрупповая дисперсия 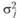 должна быть равна дисперсии экспериментальной ошибки
должна быть равна дисперсии экспериментальной ошибки 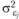 . Структурная модель дисперсионного анализа основывается на предположении о том, что все структурные компоненты оказываются независимыми друг от друга. Поэтому дисперсия ошибки не зависит от эффекта независимой переменной. Иными словами, предполагается, что величина
. Структурная модель дисперсионного анализа основывается на предположении о том, что все структурные компоненты оказываются независимыми друг от друга. Поэтому дисперсия ошибки не зависит от эффекта независимой переменной. Иными словами, предполагается, что величина 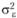 постоянна для всех экспериментальных групп, т. е. справедливо соотношение
постоянна для всех экспериментальных групп, т. е. справедливо соотношение 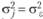 . Кроме того, предполагается, что экспериментальная ошибка распределена по нормальному закону с математическим ожиданием 0 и дисперсией
. Кроме того, предполагается, что экспериментальная ошибка распределена по нормальному закону с математическим ожиданием 0 и дисперсией 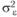 .
.
Дисперсия между экспериментальными группами складывается из дисперсии экспериментального воздействия? j и дисперсии среднего значения экспериментальной ошибки? j.
Основываясь на сделанных предположениях, можно оценить ожидаемое значение статистик MSerror и MStreatment. Но для этого необходимо сделать еще одно предположение. Оно будет состоять в том, что независимая переменная фиксирована экспериментатором, т. е. в эксперименте использованы все ее возможные значения, или уровни. Зависимая переменная случайна в том смысле, что реально полученные экспериментатором данные отражают лишь некоторые из возможных ее значений. Такая структурная модель называется фиксированной или моделью с одним случайным признаком. Ее кратко обозначают как Модель I. Существует также случайная модель однофакторного дисперсионного анализа, или модель с двумя случайными признаками. Она обозначается как Модель II. Эта модель применяется в тех случаях, когда экспериментатору нс удается зафиксировать в эксперименте все возможные значения независимой переменной вследствие того, что их число бесконечно велико. В этом случае говорят, что независимая переменная случайна. Отсюда — второй случайный признак. Следует отметить, что такое встречается нечасто. Тем не менее всякий раз исследователь должен четко осознавать, какую структурную модель он использует: первого или второго типа.
Пусть 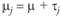 . Тогда
. Тогда 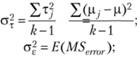
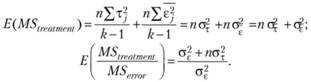
Заметим, что последнее соотношение описывает ожидаемое значение F-статистики.
Теперь можно выдвинуть две статистические гипотезы. Нулевая гипотеза будет состоять в том, что независимая переменная не оказывает никакого влияния на зависимую. Выражаясь более формально, для всех j ?j оказывается постоянной, или, что-то же самое: 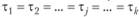
Альтернативная гипотеза будет состоять в том, что эффекты независимой переменной различны на разных уровнях. В этом случае указанное равенство не выполняется.
Если верна основная гипотеза, то 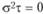 . Тогда.
. Тогда.
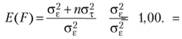
При этом статистика F будет описываться F-распределением с k — 1 степенью свободы в числителе и k (п — 1) степенью свободы в знаменателе.
Если верна альтернативная гипотеза, то 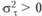 . Тогда E(F) > > 1,00. В этом случае распределение F будет отличаться от стандартного F-распределения.
. Тогда E(F) > > 1,00. В этом случае распределение F будет отличаться от стандартного F-распределения.
Единственное отличие модели с двумя случайными признаками (Модели II) состоит в том, что в ней ожидаемое значение для статистики MStreatment равно (1 — k/K)  , где К — общее число уровней независимой переменной в генеральной совокупности; k — выборочное значение К, т. е. число уровней независимой переменной, используемое в эксперименте. Поскольку в эксперименте k практически всегда много меньше К (иначе нет смысла использовать случайную модель), дробь k/K оказывается величиной настолько незначительной, что ею можно пренебречь. Таким образом, можно считать, что ожидаемые значения среднего квадрата экспериментального воздействия для случайной и фиксированной модели практически нс различаются.
, где К — общее число уровней независимой переменной в генеральной совокупности; k — выборочное значение К, т. е. число уровней независимой переменной, используемое в эксперименте. Поскольку в эксперименте k практически всегда много меньше К (иначе нет смысла использовать случайную модель), дробь k/K оказывается величиной настолько незначительной, что ею можно пренебречь. Таким образом, можно считать, что ожидаемые значения среднего квадрата экспериментального воздействия для случайной и фиксированной модели практически нс различаются.