Предмет, цель и задачи обработки естественного языка

Возможно, вы уже задались вопросом, почему для выражения одной характеристики (качества) используют сразу два критерия (полноту и точность). Ответ на этот вопрос становится ясен при разборе следующего простого примера. Пусть в корзине имеется 6 апельсинов и 6 мандаринов. Поисковому роботу дано задание — найти и выбрать из корзины только апельсины. Робот произвел две попытки: в первой он выбрал… Читать ещё >
Предмет, цель и задачи обработки естественного языка (реферат, курсовая, диплом, контрольная)
Обработка естественного языка (natural language processing) — эго дисциплина, которая изучает проблемы взаимодействия компьютеров и естественных языков. Ее целью является повышение качества машинного анализа и синтеза сообщений на естественном языке. При этом под машинным анализом понимается способность компьютера извлекать смысл из входных естественно-языковых сообщений, а под машинным синтезом — способность компьютера грамотно генерировать выходные сообщения на естественном языке. В качестве сообщений рассматриваются устные и письменные сообщения (речь и текст соответственно).
Таким образом, все задачи, которыми занимается обработка естественного языка, можно разбить на четыре больших класса: анализ речи, синтез речи, анализ текстов, синтез текстов (рис. 7.8).
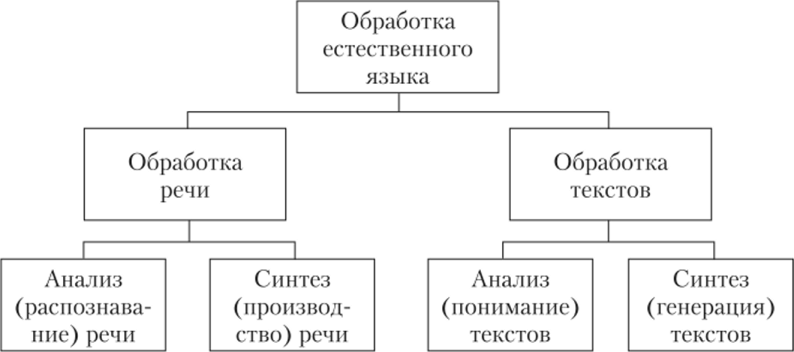
Рис. 7.8. Задачи обработки естественного языка
Ожидается, что решение этих четырех задач существенно повысит качество и эффективность взаимодействия человека и компьютера. Поэтому дисциплину обработки естественного языка включают в состав наук, занимающихся вопросами человекокомпьютерного (человеко-машинного) взаимодействия (humancomputer interaction).
Приведенное распределение задач обработки естественного языка по четырем классам полезно в теоретическом смысле. Однако в практическом отношении оно бессмысленно, так как многие прикладные задачи обработки естественного языка невозможно отнести к какому-то одному классу. Например, разработка вопросно-ответных систем, способных принимать вопросы и отвечать на них на естественном языке, — это сложная практическая задача, относящаяся как минимум к двум классам (понимание и генерация текстов).
К числу наиболее известных прикладных задач машинного анализа текстов на естественном языке относятся:
- • машинный перевод (machine translation);
- • информационный поиск (information retrieval);
- • автоматическая классификация и кластеризация текстов {automatic text classification and clustering);
- • автоматическое реферирование и аннотирование текстов {automatic text summarization and annotation);
- • автоматическое извлечение фактов (знаний) из текстов {information extraction, knowledge discovery);
- • разработка автоматических вопросно-ответных систем {question-answering systems development).
Самые ранние исследования в области обработки естественного языка были связаны именно с решением практических задач. Так, в 1954 г. в США была проведена первая публичная демонстрация системы машинного перевода с русского на английский язык, выполненного на машине IBM-7011. Хотя алгоритм перевода, используемый в системе, не обладал особой научной ценностью, само появление такой системы дало мощный толчок исследованиям в области машинного анализа текстов не только в США, но и за их пределами. В СССР первый перевод с английского языка на русский был получен с помощью машины БЭСМ в 1955 г.[1][2]
Идея использовать вычислительные машины для информационного поиска была предложена в 1945 г.[3] В 1948 г. появились сообщения о машине Univac, способной выполнять поиск документа по его тематическому коду, записанному вместе с текстом документа[4]. В 1960—1970;х гг. исследовательская группа, возглавляемая Дж. Салтоном, разработала руководящие принципы информационного поиска, в числе которых была предложена и векторная модель поиска {vector space model), лежащая в основе всех современных поисковых систем[5].
Векторная модель представляла документы и поисковые запросы как векторы в ЛГ-мерном пространстве {N равнялось размерности словаря коллекции документов). Близость между документом и запросом измерялась на основе близости соответствующих векторов. Чем меньше был угол между векторами, тем выше считалось соответствие документа запросу (рис. 7.9). В качестве метрики близости использовалась косинусная мера, т. е. значение косинуса угла между соответствующими векторами.
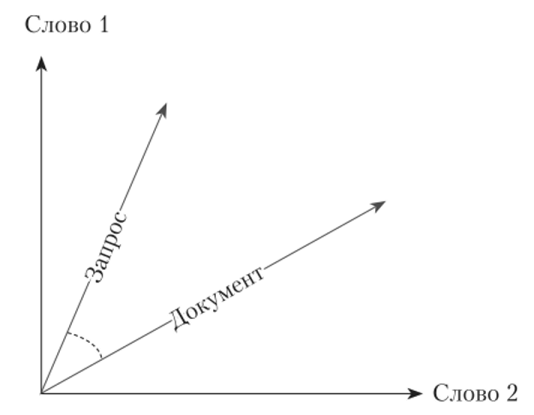
Рис. 7.9. Векторная модель информационного поиска.
В силу своей мощности, универсальности и простоты векторная модель мгновенно стала хитом не только в информационном поиске, но и в других приложениях машинной обработки текстов.
Для обозначения близости между документом и запросом были введены термины «релевантность» и «пертинентность». Релевантными считаются документы, содержание которых соответствует поисковому запросу с точки зрения поисковой машины. В отличие от них, пертинентными считаются документы, содержание которых соответствует поисковому запросу с точки зрения пользователя. В идеале множества релевантных и иергинентных документов должны совпадать, но в реальности они не совпадают, а пересекаются (рис. 7.10). Причем чем больше область пересечения, тем выше качество поиска. Другими словами, если бы поисковая машина могла прочесть и понять текст каждого документа коллекции так, как это сделал бы человек, то качество поиска было бы стопроцентным. Но, как мы уже не раз говорили, машина не может обрабатывать и понимать тексты как человек в силу того, что естественный язык — это плохо формализуемая система. Таким образом, в основании задачи информационного поиска лежит все та же проблема формализации естественного языка.
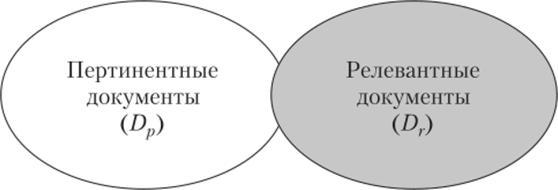
Рис. 7.10. Пересечение множеств релевантных и пертинентных.
документов Для оценки качества информационного поиска используются такие критерии, как полнота и точность. Полнотой поиска называется отношение числа пертинентных документов, найденных поисковой машиной, к общему числу пертинентных документов. Точностью поиска называется отношение числа пертинентных документов, найденных поисковой машиной, к общему числу релевантных документов.
Если обозначить множество релевантных документов через Dr а множество пертинентных документов через Dpi то точность и полнота будут выражаться соответственно следующими формулами:

где значок «|| ||» обозначает мощность (размер) множества, указанного внутри этого значка.
Обратившись снова к рис. 7.9, можно сказать, что полнота символизирует процент площади пересечения в левом круге, а точность — процент площади пересечения в правом круге. Поскольку полнота и точность зависят от числа пертинентных документов, то их значения рассчитывают только на тестовых коллекциях, для которых заранее известно это число.
Возможно, вы уже задались вопросом, почему для выражения одной характеристики (качества) используют сразу два критерия (полноту и точность). Ответ на этот вопрос становится ясен при разборе следующего простого примера. Пусть в корзине имеется 6 апельсинов и 6 мандаринов. Поисковому роботу дано задание — найти и выбрать из корзины только апельсины. Робот произвел две попытки: в первой он выбрал все 6 апельсинов и все 6 мандаринов, во второй — 3 апельсина. Очевидно, что обе попытки неудачные, но каждая по-своему. Сведя результаты попыток в таблицу, можно определить полноту и точность поиска для каждого случая (табл. 7.4).
Таблица 7.4
Результаты попыток поискового робота
Номер попытки. | Результат работы. | Полнота. | Точность. |
Робот выбрал 6 апельсинов и 6 мандаринов. | 100% (все 6 апельсинов выбраны: 0 ложных пропусков). | 50% (половина выбранных фруктов — не апельсины: 6 ложных срабатываний). | |
Робот выбрал 3 апельсина и 0 мандаринов. | 50% (из 6 апельсинов выбрано только 3: 3 ложных пропуска). | 100% (все 3 выбранных фрукта — апельсины: 0 ложных срабатываний). |
Как видно из табл. 7.4, ни 100%-я полнота (попытка 1), ни 100%-я точность (попытка 2) но отдельности не являются залогом высокого качества поиска.
Качество обеспечивается компромиссом между полнотой и точностью, при этом разработчики поисковых систем стараются, чтобы оба критерия были как можно выше. Но поскольку в реальных системах, как правило, невозможно одновременно достичь высокой полноты и точности, го зачастую используются гармонизированные метрики качества[6].
Так, точность и полноту объединяют в среднее гармоническое, которое называют Е-мерой:
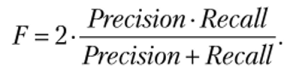
Следует отметить, что проблематика информационного поиска в целом шире, чем проблема формализации и моделирования естественного языка. Дело в том, что в условиях информационного взрыва, который переживает современное общество, задача информационного поиска приобретает новую актуальность.
Под информационным взрывом понимается экспоненциальный рост объемов информации, являющийся сегодня глобальным трендом общественного развития. Его главное последствие заключается в том, что информационное пространство становится все более неупорядоченным, а процессы обработки информации (включая процессы поиска) становятся все более сложными, трудоемкими и неэффективными.
В связи с этим актуализируется потребность в исследовании новых принципов и подходов к обработке информации. Главный экономист Google X. Вариан сформулировал эту потребность следующим образом: «Данные становятся настолько широкодоступными, что не хватает способностей извлекать из них знания»1. Так емко и лаконично в компании Google определили один из главных научно-технологических вызовов современности — феномен больших данных.
Продемонстрируем один из механизмов улучшения качества информационного поиска — коллаборативной фильтрации. Если вернуться к изречению X. Вариана, то можно сказать, что информационное изобилие — это один из сложнейших вызовов, на который предстоит ответить науке информационного поиска. Использование коллаборативной фильтрации — эго один из ответов на такой вызов.
Коллаборативной фильтрацией называется метод прогнозирования неизвестных предпочтений пользователя путем сбора и обработки информации о предпочтениях сообщества пользователей. Основой для коллаборативной фильтрации является матрица предпочтений пользователей, которую формируют рейтинги (оценки), выставленные пользователями каким-то объектам, например фильмам (табл. 7.5).
Таблица 75
Матрица предпочтений пользователей
Зри; тель. | Фильм. | Средний рейтинг. | |||
«Аватар». | «Отступник». | «1+1». | «Территория». | ||
Алия. | 8,75. | ||||
Игорь. | — со. | ||||
Алексей. | 7,5. | ||||
Ержан. | ?(0). | 8,67. | |||
1 «Data are widely available; what is scarce is the ability to extract wisdom from them» (приводится no: Cukier K. Data, Data Everywhere: A Special Report on Managing Information // The Economist. 2010. jN" 8671 (394)).
На основе матрицы предпочтений определяется сходство между любыми двумя пользователями. Сходство может быть рассчитано с помощью косинусной меры, которая являет собой универсальную метрику близости в векторно-пространственных моделях:
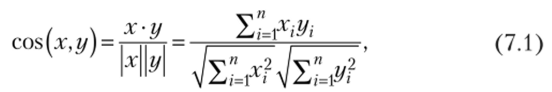
где х = (хХу …, хп) и у = (г/j, уп) — это векторы в я-мерном пространстве, заданные своими координатами.
Согласно формуле (7.1) сходство между пользователями Алия и Алексей равно:
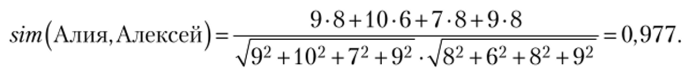
Попарные сходства между пользователями приведены в матрице сходства (табл. 7.6).
Таблица 7.6
Матрица сходства пользователей.
Сходство. | Алия. | Игорь. | Атексей. | Ержан. |
Алия. | 0,893. | 0,977. | 0,834. | |
Игорь. | 0,893. | 0,819. | 0,736. | |
Алексей. | 0,977. | 0,819. | 0,847. | |
Ержан. | 0,834. | 0,736. | 0,847. |
Неизвестное значение рейтинга, который может назначить объекту i пользователь и, прогнозируется с помощью следующей формулы:

где — это среднее значение известных рейтингов объекта г k — это индекс, который пробегает множество всех пользователей, кроме пользователя и; rk — это среднее значение известных рейтингов, выставленных пользователем k; sim (u, k) — это сходство между пользователем и и пользователем к, определяемое по матрице еходетва.
Так, используя формулу (7.2), можно спрогнозировать рейтинг, который выставил бы пользователь Ержан фильму «Аватар»:

Еще одна интересная задача обработки естественного языка — это сентимент-анализ. Искусственный интеллект уже сейчас способен на многое: обыгрывать людей в шахматы, решать сложные задачи по математике, автоматически сортировать новости и т. д. Следующий шаг — построение «социализированного» искусственного интеллекта, способного понимать не только смысл текстов, но и эмоции, содержащиеся в них. Именно такие проблемы стоят перед одним из самых молодых направлений обработки естественного языка — дисциплиной сентимент-анализа.
Сентимент-анализ (sentiment analysis), или анализ тональности текстов, — это дисциплина, которая изучает методы и алгоритмы извлечения мнений и эмоций из текстовых сообщений. Сентимент-анализ очень востребован в социологии и политологии (при сборе и анализе мнений из социальных сетей), в маркетинге (при оценке отзывов потребителей, например потребителей определенных товаров, услуг или брендов), в психологии и медицине (при анализе текстов для выявления депрессивных, агрессивных или других состояний пациентов, при предупреждении суицидов) и т. д. Существует четыре основных класса подходов, применяемых в сентимент-анализе:
- • подходы, основанные на правилах;
- • подходы, основанные на словарях;
- • подходы, основанные на машинном обучении с учителем;
- • подходы, основанные на машинном обучении без учителя.
Автор одной из публикаций о сентимент-анализе[7] приводит пример гибридного подхода, основанного на правилах и словарях: «Если сказуемое входит в положительный набор глаголов и в предложении не имеется отрицаний, то классифицировать тональность как положительную». Таким образом, для текста «Я люблю кофе» при наличии положительного словаря глаголов {любить, обожать, ценить, одобрять…} оценка тональности будет положительной. Недостаток такого подхода связан с тем, что требуется составить большое количество правил и словарей и, кроме того, некоторые правила могут противоречить друг другу.
Чтобы познакомиться с остальными подходами, мы вам рекомендуем обратиться к указанной публикации, а пока рассмотрим задачу сенгимент-анализа под другим, возможно, несколько неожиданным ракурсом. Автором данной, очень интересной и нестандартной, задачи является И. Кобозева[8].
Вначале автор предлагает сравнить близкие по значению предложения:
Думаю, что Ивана простили. (1) Боюсь, что Ивана простили. (2) Надеюсь, что Ивана простили. (3).
Все они выражают некоторую долю уверенности говорящего в событии «Ивана простили», но, кроме того, в (2) и (3) выражено отношение говорящего к этому событию: отрицательное в (2) и положительное в (3). Смысловые различия между (1), (2) и (3) очевидным образом связаны со словами «думать», «бояться» и «надеяться». В отличие от «думать», слова «бояться» и «надеяться» заключают в своем значении оценку (оценочную пресуппозицию) говорящего:
- • «я боюсь, что Р» — «я считаю, что Р плохо»;
- • «я надеюсь, что Р» — «я считаю, что Р хорошо».
Слов, находящихся в таких же смысловых отношениях, как «думать — бояться — надеяться», в русском языке не так уж мало. Таблица 7.7 устроена следующим образом: слова (или словосочетания), стоящие в одной строке в первых трех столбцах, должны различаться по значению только оценочными пресуппозициями (нейтральное отношение / отрицательная оценка / положительная оценка) события, выраженного подчиненной им фразой (предложением или словосочетанием). Пример такой фразы содержится в четвертом столбце табл. 7.7.
Форма для внесения оценочных пресуппозиций.
Таблица 7.7
Отношение к событию Р. | Пример фразы, выражающей событие Р. | ||
не выражено. | отрицательное. | положительное. | |
довелось. |  | видеть эго. | |
подвигнуть на. | такой поступок. | ||
дойти до. |  |  | такого положения в обществе. |
 |  |  | он не понимал по-русски. |
произошло. |  |  | нечто неожиданное. |
 | пожертвовал. | привычкой читать лежа. | |
Задача. Заполните пустые (незатемненные) клетки табл. 7.7.
У некоторых клеток может быть несколько вариантов заполнения. Обратите внимание: примеры в четвертом столбце таблицы приводятся в такой форме, чтобы они сочетались со словами, данными в первых трех столбцах. Слова (или словосочетания), предлагаемые вами для заполнения клеток в первых трех столбцах, могут требовать и несколько другой формы отдельных слов в описании события Р, например другого падежа существительного.
Решение. Дадим авторское решение этой задачи, дополнив его частью своих примеров (табл. 7.8).
Таблица 7.8
Примеры оценочных пресуппозиций
Отношение к событию Р. | Пример фразы, выражающей событие Р. | ||
не выражено. | отрицательное. | положительное. | |
довелось. |  | посчастливилось, повезло. | видеть это. |
побудить, склонить на. | подбить на, подстрекнуть к, подзудить к. | подвигнуть на, вдохновить на. | такой поступок. |
дойти до. |  |  | такого положения в обществе. |
 |  |  | он не понимал по-русски. |
произошло. |  |  | нечто неожиданное. |
расстался, отказался от. |  | пожертвовал. | привычкой читать лежа. |
Вот как комментирует сам автор свое решение: «Эта задача интересна тем, что ее „абсолютно правильного“ решения не существует. Языковое чутье разных людей может значительно расходиться, и то, что правильно в одном идиолекте (индивидуальном варианте языка), носителю другого идиолекта может показаться сомнительным и даже неверным».
- [1] См.: Hutchins J. Machine Translation: A Concise History // Computer AidedTranslation: Theory and Practice / ed. by S. W. Chan. Hong Kong: Chinese Universityof Hong Kong, 2007.
- [2] Панов Д. Ю., Ляпунов A. A., Мухин И. С. Автоматизация перевода с одногоязыка на другой // Сессия по научным проблемам автоматизации производства.М.: Изд-во АН СССР, 1956.
- [3] Singhal A. Modern Information Retrieval: A Brief Overview // Bulletin of theIEEE Computer Society Technical Committee on Data Engineering. 2001. № 4 (24).
- [4] Sanderson M., Croft W. B. The History of Information Retrieval Research //Proceedings of the IEEE. 2012. Vol. 100.
- [5] Salton G., Wong A., Yang C. S. A vector space model for automatic indexing //Communications of the ACM. 1975. № 11 (18).
- [6] Сычев А. В. Информационно-поисковые системы // MyShared. URL: http://wvvw.mysharcd.ru/slidc/370 967
- [7] Обучаем компьютер чувствам (sentiment analysis по-русски) // Хабрахабр.2012. 15 августа. URL: https://habrahabr.ru/post/149 605
- [8] См.: Задачи лингвистических олимпиад. 1965—1975 / ред.-сост. В. И. Беликов, Е. В. Муравенко, М. Е. Алексеев. М.: Изд-во МЦНМО, 2006.