Анализ статистических связей: введение

Почему в данном случае мы в состоянии определить функциональную связь между X и У? Во-первых, потому, что сама функция F — правило перевода голосов в депутатские мандаты — явным образом определена в соответствующих нормативных актах. Этот закон создан государством и находится под его контролем: можно изменить, например, параметр связи (величину заградительного барьера) и получить предсказуемые… Читать ещё >
Анализ статистических связей: введение (реферат, курсовая, диплом, контрольная)
Понятие статистической связи
В центре внимания всех наук находятся связи между явлениями. Любой закон физики, например, представляет собой математическое описание зависимости поведения одной переменной от набора других переменных, с одной стороны, и некоторого набора постоянных величин (параметров функции) — с другой. Иначе говоря, закон представляет собой функцию

связывающую величину Y с множеством величин X (вектором X) и множеством параметров 0 (вектором 0). Функция определяет, каким образом элементы одного множества должны быть соотнесены (сопоставлены) с элементами другого множества. Возьмем простейшую линейную функцию Y= kX. Она представляет собой правило, позволяющее определенному значению переменной X поставить в соответствие определенное значение переменной Y. Согласно этому правилу нужно значение X умножить на постоянную к, представляющую собой параметр линейной связи. Иными словами, изменения в значениях переменной X приводят к пропорциональному (коэффициент пропорциональности — к) изменению в значениях переменной Y. В любом случае функциональная связь представляет собой связь между значениями одной переменной и значениями другой переменной.
Существуют ли функциональные связи в политике? Да, существуют. Например, зная долю голосов, полученных партиями на выборах депутатов Государственной Думы, мы можем совершенно точно рассчитать число мест, которые каждая партия получит в нижней палате парламента. Для этого, конечно, надо знать нормы избирательного законодательства, регулирующие распределение мест в Госдуме по итогам голосования.
Итак, существует функция, сопоставляющая электоральному результату партии (X) число мест в Государственной Думе (У):

где Q — вектор результатов других партий; s — величина заградительного барьера (параметр).
Почему в данном случае мы в состоянии определить функциональную связь между X и У? Во-первых, потому, что сама функция F — правило перевода голосов в депутатские мандаты — явным образом определена в соответствующих нормативных актах. Этот закон создан государством и находится под его контролем: можно изменить, например, параметр связи (величину заградительного барьера) и получить предсказуемые изменения в распределении мест. Вовторых, четко определен круг переменных, от которых зависит число депутатских мандатов у политической партии. Оно зависит от числа голосов, полученных ею на выборах, от числа голосов, полученных другими партиями, и болев ни от чего.
Рассмотрим другую ситуацию. Допустим, мы исследуем связь между долей мигрантов в стране (М) и уровнем материального благополучия ее граждан, самым простым индикатором которого является ВВП надушу населения (GDP). Содержательно мы можем обосновать гипотезу о наличии такой связи и ее характере: миграционные потоки должны быть, в основном, направлены из неблагополучных стран в благополучные. Соответственно, для благополучных стран должна быть характерна большая доля мигрантов. Так и обстоит дело на самом деле, это подтверждают эмпирические исследования.
Но является ли описанная нами связь функциональной? Иными словами, можем ли мы на основании данных о ВВП на душу населения в определенной стране точно предсказать долю мигрантов? Очевидно, нет. Главным образом это обусловлено тем, что миграционные потоки зависят от множества факторов, в число которых входит уровень благополучия. Одним из таких факторов является миграционное законодательство, в силу которого одни страны принимают мигрантов охотно, другие — практически не принимают.
Другой фактор связан с социальной и политической обстановкой в странах, которые являются источником миграции. Скажем, колебания в уровне социальной и политической напряженности приводят к изменениям в миграционных потоках. Так, этнические конфликты почти всегда порождают всплеск миграции. Наконец, на миграцию влияют и практически не поддающиеся систематическому учету факторы субъективного характера.
Нельзя забывать и об ошибках измерения. Значительная часть миграции оказывается нелегальной, и, соответственно, данные официальной статистики не отражают реального количества мигрантов. Измерения ВВП на душу населения также не дают стопроцентно точных результатов; в этой связи показательно, что в современной экономике существует по крайней мере три альтернативных способа оценки этого показателя.
Таким образом, более адекватной рассматриваемым переменным оказывается не модель функциональной связи (8.1), а модель статистической связи:

где е — случайная ошибка, включающая неучтенные факторы и неточности в измерениях.
Итак, статистический подход раскладывает исследуемую переменную на две составляющие: закономерную часть (функцию) и случайную часть (ошибку) (рис. 8.1).
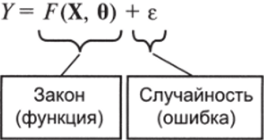
Рис. 8.1.
Мы определили общие контуры математической модели статистической связи, но не дали ее строгого определения. Пока ясно лишь, что статистическая связь, в отличие от функциональной, не позволяет сопоставить значения зависимой переменной значениям независимой. Тогда какое соответствие определяется статистической связью? Чтобы ответить на этот вопрос, нам понадобится понятие условной вероятности, без которого невозможно понять, что представляет собой статистическая связь.
Условная вероятность представляет собой вероятность осуществления некоторого события А при условии, что произошло событие В. Записывается Р (АВ) следует запомнить, что перед вертикальной чертой фиксируется событие, вероятность наступления которого нас интересует, после черты — условие (аргумент). Вначале разберем пример, основанный на классической модели вероятности. Речь пойдет о двукратном подбрасывании игральной кости, пространство элементарных исходов этого испытания приведено в табл. 8.1 (она знакома нам по главе 3). Пусть событие А заключается в том, что хотя бы на одной кости выпала единица. Этому событию благоприятствует 11 исходов, в таблице они выделены полужирным шрифтом. Всего исходов 36. По классической схеме исходы равновероятны, следовательно, «безусловная» вероятность события А составляет 11/36.
Нам также дополнительно известно, что сумма выпавших очков не превысит 6; в этом состоит событие В — условие. Событию В благоприятствует 15 исходов (выделены курсивом). Вероятность В, таким образом, составляет 15/36.
Таблица 8.1
Кубик 1. | Кубик 2. | |||||
Г.7.?"**-. | (1,2} | (1,3} | 0,4} | (1,5} | {1,6}. | |
(2,1/ | (2,2} | (2,3} | (2,4} | {2,5}. | {2,6}. | |
(3,1) | (3,2} | /3,3} | {3,4}. | {3,5}. | {3,6}. | |
14 и | (4,2} | {4,3}. | {4,4}. | {4,5}. | {4,6}. | |
{5,2}. | {5,3}. | {5,4}. | {5,5}. | {5,6}. | ||
(б.". | {6,2}. | {6,3}. | {6,4}. | <6,5}. | {6,6}. | |
Нам нужно рассчитать вероятность того, что выпадет хотя бы одна единица (А) при условии, что сумма очков не превысит 6 (В). Формула для условной вероятности такова:

P (AB) в числителе правой части — это вероятность пересечения событий А и В, все те исходы, которые одновременно благоприятствуют и А, и В. Таких исходов 9 (выделено заливкой), следовательно, Р (АВ) = 9/36. В знаменателе правой части находится вероятность события В — вероятность условия. Она равна, как нам уже известно, 15/36. Таким образом:
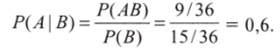
Вероятность того, что выпадет хотя бы одна единица при условии, что сумма очков не превысит шести, составляет 0,6. Обратите внимание, что «безусловная» вероятность выпадения единицы существенно ниже — 11/36 = 0,3. События А и В являются зависимыми, так как реализация В влияет на вероятность реализации А. Для независимых событий справедливо.

т.е. условная вероятность равна безусловной; событие В не оказывает здесь никакого влияния на вероятность А.
Имея в нашем багаже понятие условной вероятности, мы можем перейти непосредственно к концепту статистической связи. Допустим, нас интересует влияние пола респондента на его участие в выборах. Обе переменные являются номинальными. Категории (значения) переменной «пол»: 1 — мужской, 2 — женский; значения переменной «участие в выборах»: 1 — участвует, 2 — не участвует (результаты социологического опроса см. в табл. 8.2).
В исследуемой совокупности объемом 100 человек 50 мужчин и 50 женщин. В выборах участвовало 60 человек, не участвовало 40. Эти числа характеризуют распределения переменных «пол» и «участие» по отдельности. Но, чтобы ставить вопрос о статистической связи, этого не достаточно. Требуется информация об их совместном распределении. Для категориальных переменных основным инструментом анализа совместных распределений являются матрицы (табли-
Таблица 8.2
№ респондента | Пол | Участие | № респондента | Пол | Участие | № респондента | Пол | Участие | № респондента | Пол | Участие |
цы) сопряженностей. Они показывают частоты одновременного, совместного появления категорий двух переменных. Для нашего примера такой матрицей является табл. 8.3.
Таблица 8.3
Пол. | Участие. | Всего. | |
Участвовал (1). | Не участвовал (2). | ||
Мужской (1). | |||
Женский (2). | |||
Всего. | |||
Прежде чем идти дальше, ознакомимся с базовыми сведениями о матрицах. Матрица обозначается большой латинской буквой А, при записи в виде таблицы иногда ее выделяют скобками, квадратными скобками или двойными вертикальными линиями: (А), [А, || А ||. Числа, составляющие матрицу, называются ее элементами и обозначаются той же буквой, что и сама матрица, но строчной: а0. У каждого элемента матрицы два нижних индекса, первый из которых (/) обозначает номер строки, в которой стоит элемент. Запись типа «/ = 1, т» означает, что нумерация строк производится от 1 до /и, где т — общее число строк в матрице. Второй индекс (/) обозначает номер столбца, в котором находится элемент, j = 1, п.
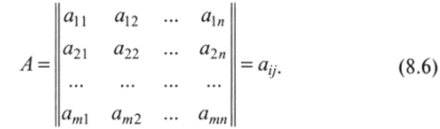
т.
Сумма элементов в строке обозначается сумма в столбце — ^яу, °бшая сумма — ^air
j=i
В нашей задаче при заполнении ячейки, к примеру, я,2, фиксирующей число респондентов-мужчин, не принявших участие в голосовании, мы подсчитываем количество случаев одновременного появления значения 1 переменной «пол» и значения 2 переменной «участие»; ап — 30 (в табл. 8.4 эти случаи выделены полужирным шрифтом).
Таблица 8.4
№ респондента | Пол | Участие | № респондента | Пол | Участие | № респондента | Пол | Участие | № респондента | Пол | Участие |
Рассчитаем условные вероятности участия и неучастия в выборах в зависимости от пола респондента. Для этого, вопервых, необходимо перейти от матрицы сопряженностей частот к матрице сопряженностей вероятностей. В данном случае исходы не симметричны, и мы воспользуемся статистической моделью вероятности как относительной частоты.
Упражнение 8.1
- 1. Внесите табл. 8.3 на лист программы Excel.
- 2. Рассчитайте вероятности для всех ячеек, включая те, которые содержат суммы. Для этого разделите значение в каждой ячейке на общую частоту ^а,. = 100. Воспользуйтесь функциями, как это показано на рис. 8.2. Так как деление идет на одну и ту же ячейку, технически удобно зафиксировать ее с помощью значков «$».[1]

Рис. 8.2
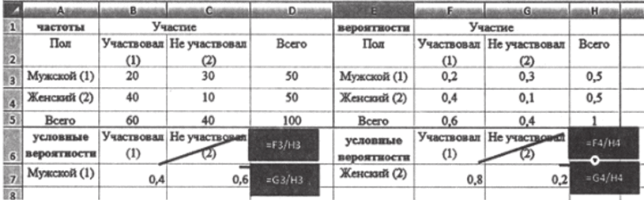
Рис. 8.3.
независимая переменная принимает какое-то определенное значение, можно считать аргумент зафиксированным. При фиксированном аргументе 1 (мужчина) условная вероятность участия составляет 0,4, неучастия — 0,6. При переходе к аргументу 2 (женщина) условная вероятность участия составляет 0,8, неучастия — 0,2. Переход от одного значения аргумента к другому означает в данном случае, что сначала мы оценивали вероятность участия и неучастия только среди мужчин, затем — только среди женщин.
Таким образом, переменная «участие» реагирует на изменение значения переменной «пол» своим распределением условных вероятностей (рис. 8.4).

Рис. 8.4.
Это и составляет сущность статистической связи. При наличии статистической связи изменение значения одной переменной (независимой) приводит к изменению условного распределения вероятностей другой переменной (зависимой).
Сравним статистическую связь с функциональной, через призму этого определения. Если бы пол и участие в выборах были связаны функционально, тогда изменение значения переменной «пол» (мужчины или женщины) вело бы к изменению значения переменной «участие». Иначе говоря, явка на выборы полностью определялась бы полом избирателя; для такого сложного явления, как электоральная активность, это трудно представить. При наличии статистической связи мы утверждаем лишь, что мужчины и женщины могут различаться вероятностными характеристиками участия: вероятность проголосовать будет выше у женщин (в нашем примере), чем у мужчин.
Чтобы запомнить различия между функциональной и статистической связью, составим следующую таблицу:
Таблица 8.5
Тип связи. | Меняется у независимой переменной. | Меняется у зависимой переменной. |
Функциональная. | Значение. | Значение. |
Статистическая. | Значение. | Распределение условных вероятностей. |
Для закрепления понимания статистической связи полезно будет исследовать ситуацию, когда связь между переменными отсутствует. Вернемся к матрице сопряженностей 8.3. Оставим в ней суммарные частоты неизменными. В ячейках совместного распределения нам нужно подобрать такие частоты, чтобы изменение значения переменной «пол» не приводило к изменению распределения условных вероятностей переменной «участие» (см. табл. 8.6).
Таблица 8.6
Участие. | |||
Пол. | Участвовал (1). | Не участвовал (2). | Всего. |
Мужской (1). | |||
Женский (2). | |||
Всего. | |||
Для решения такой задачи существует специальная формула, которая пригодится нам в дальнейшем при измерении характеристик статистической связи. Ее идея состоит в том, что частоты в отдельных ячейках должны полностью определяться суммарными показателями:
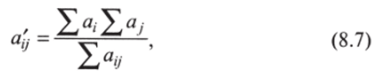
где a’j — частоты совместного распределения, при которых связь отсутствует; ?я, — сумма частот в строке, в которой стоит элемент; ?яу — сумма частот в столбце, в котором стоит элемент;? я,; — общая сумма частот.
Возьмем ячейку аи в табл. 8.6. Элемент стоит в первой строке, где сумма частот составляет 50 (всего мужчин), и в первом столбце, где сумма частот составляет 60 (всего участвует). Общая сумма частот составляет 100 (общее число респондентов). По формуле (8.7):
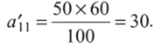
Рассчитаем остальные частоты, используя Excel.
Упражнение 8.2
1. В качестве заготовки используйте лист с данными и функциями, полученный в п. 3 упражнения 8.1 (рис. 8.3). В ячейки исходной матрицы частот введите функции, соответствующие формуле (8.7), как это показано на рис. 8.5.[2]

Рис. 8.5.
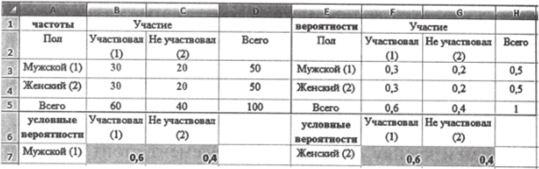
Рис. 8.6.
Теперь изменение значения переменной «пол» никак не отражается на условном распределении вероятностей переменной участия. Следовательно, статистическая связь отсутствует.
- [1] Рассчитаем вероятность участия в выборах при условии, что респондент — мужчина. Интересующее событие —"участвовал" (столбец 1), условие — «мужской» (строка 1).Пересечение категорий находится в ячейке аи, вероятностьсоставляет 0,2. Вероятность условия — события «мужской» — равна 0,5 (сумма в первой строке). По формуле (8.4): Таким же образом рассчитаем все остальные условныевероятности (см. рис. 8.3). Для каждого значения независимой переменной «пол"мы получили распределение условных вероятностей. Когда
- [2] Посмотрите, как изменились условные распределениявероятностей (рис. 8.6). Так как для расчета условных вероятностей в упражнении 8.1 мы использовали функции, весьпересчет должен осуществиться автоматически.