Обзор существующих решений

В начале алгоритма все экземпляры объектов представлены как отдельные кластеры. Первый шаг отбирает наиболее похожие объекты, формирую из них кластер. С каждым последующим шагом происходит формирование новых кластеров, а так же объединение кластеров в группы. Так продолжается пока не будет сформирован конечный кластер, содержащий в себе другие кластеры. Во время работы алгоритма кластеры… Читать ещё >
Обзор существующих решений (реферат, курсовая, диплом, контрольная)
Иерархические методы кластеризации
Основой иерархической кластеризации является последовательное слияние кластеров для образования больших структур или разделение больших кластеров на меньшие. Такая кластеризация зачастую имеет очень хорошую наглядность, но её используют лишь при небольших объёмах наборов данных.
Иерархические методы кластеризации различны по правилам формирования кластеров. Правила используются для определения схожи ли объекты между собой и могут ли они быть отнесены в один кластер. Методы, соединяющие экземпляры в группы называются агломеративными, а разделяющие — дивизимными[30].
В графической аналогии иерархические методы базируются на построении дендрограмм (от греческого dendron — «дерево»), которые описывают расстояния между отдельными точками и кластерами друг по отношению к другу.
Далее каждый вид будет рассмотрен отдельно через своих попоулярных представителей.
Агломеративные AGNES (Agglomerative Nesting).
Эта группа методов, как было сказано ранее, характеризуется последовательным объединением исходных элементов и соответствующим уменьшением числа кластеров.
В начале алгоритма все экземпляры объектов представлены как отдельные кластеры. Первый шаг отбирает наиболее похожие объекты, формирую из них кластер. С каждым последующим шагом происходит формирование новых кластеров, а так же объединение кластеров в группы. Так продолжается пока не будет сформирован конечный кластер, содержащий в себе другие кластеры.
CURE.
Этот алгоритм предназначен для кластеризации очень больших наборов числовых данных, только эффективно работать способен с данными низкой размерности.
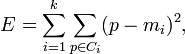
Алгоритм основан на наборе определяющих точек. Сначала алгоритм формирует дерево кластеров, где каждый объект является кластером единичного размера. Затем кластеры сортируются по расстоянию друг от друга, используя «манхэттенское» или «евклидово» расстояние. После формирования этих данных в «куче» оперативной памяти, происходит слияние ближайших кластеров и пересчёт расстояний. Так происходит до получения нужного количества кластеров.
Во время работы алгоритма кластеры разделяются на две группы: первая группы — кластеры у которых вычисляется минимальное расстояние с новообразованным кластером, вторые — все остальные кластеры. При смене кластеров и новом пересчёте происходит чередование кластеров с которыми происходит сравнивание.
Таким образом, алгоритм является высокоуровневым алгоритмом кластеризации, выделяет кластеры различных форм и имеет линейную зависимость к размеру хранимых данных и временной сложности.
ROCK.
Алгоритм кластеризации ROCK. Robust Clustering Algorithm — агломеративный иерархический алгоритм, для кластеризации большого количества данных с номинальными (булевыми) атрибутами[34].
Алгоритм по работе схож с K-means, но он учитывает наличие связи у общих соседей. Работа алгоритма построена на составлении матриц схожести. Это матрицы соседства кластеров, количества общих соседей, меры близости объектов. Соседство кластеров определяется отношением конъюнкции и суммы по модулю 2 двух кластеров. Формула определения близости объектов зависит количества объектов в каждом кластере и общих ссылок между двумя кластерами. После формирования матриц начинается итеративная кластеризация, находящая двух наиболее близких кластера, и объединяя их. При этом формируются новые значения в матрице общих ссылок и матрице близости, а данные о двух оригинальных кластерах удаляются. Критериями для завершения итераций являются либо достижения заданного их числа, либо сформировано указанное количество кластеров, все расстояния между кластерами нулевые или сформирован кластер больше заданного размера.
Дивизимные DIANA (Divisive Analysis):
Методы этой группы логически противоположны агломеративным, в начале их работы объекты находятся в одном кластере. В результате работы алгоритмов на каждом их шаге такой кластер будет делиться на меньшие, создавая последовательность расщепляющих групп[33].
BIRCH.
Алгоритм предложен Тьян Зангом и его коллегами[37].
Достоинства алгоритма лежат в его высокой скорости на фоне большой масштабируемости. Это достигается за счёт двухэтапного процесса кластеризации.
На первом этапе алгоритм формирует предварительный набор кластеров. Второй этап применяет к выделенным кластерам иные методы кластеризации, что делает этот очень нетребовательным к ресурсам.
Тьян Занг приводит следующую аналогию в отношении алгоритма BIRCH: «Если каждый элемент данных представить себе как бусину, лежащую на поверхности стола, то кластеры бусин можно „заменить“ теннисными шариками и перейти к более детальному изучению кластеров теннисных шариков. Число бусин может оказаться достаточно велико, однако диаметр теннисных шариков можно подобрать таким образом, чтобы на втором этапе можно было, применив традиционные алгоритмы кластеризации, определить действительную сложную форму кластеров.».
MST.
Этот алгоритм основан на построении минимального остовного дерева (MST, minimum spanning tree). Граф строится на основании представления объектов как вершин, а расстояний между этими объектами как дуг. На полученный граф применяется метод построения минимального остовного дерева, причём может применяться любой известный метод, но с учётом большого числа дуг в графе (при N документах в коллекции — дуг). После этого удаляются ребра с наибольшими длинами, образуя лес небольших деревьев, узлы которых порождают кластеры.
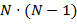
Это достаточно гибкий алгоритм, кластеризующий произвольные наборы данных, выделяя кластеры различных форм, и выбирая наиболее оптимальное решение. Скорость работы будет во многом зависеть от выбранного метода получения минимального остовного дерева.