Методы и модели сглаживания временных рядов

Какое же значение следует выбрать при использовании этой модели? Некоторые специалисты рекомендуют значения, а = 0,1, или, а = 0,2, или, во всяком случае, не больше 0,3. Другие исследования показывают, что значения, а > 0,3 для некоторых рядов обеспечивают лучший прогноз, чем меньшие значения а. Поэтому лучше оценить качество прогноза для нескольких различных значений а. Многие статистические… Читать ещё >
Методы и модели сглаживания временных рядов (реферат, курсовая, диплом, контрольная)
1. Наиболее часто используемым подходом к прогнозированию при анализе временных рядов является сглаживание на основе скользящего среднего (moving averages). Сглаживание временного ряда означает представление тренда в данной точке посредством среднего значения ряда, вычисленного в окрестности данной точки. Используемое для сглаживания количество точек в окрестности называют базой (span). Как правило, в качестве окрестности точки принимаются значения ряда, предшествующие данной точке (т.е. сглаженный ряд меньше исходного ряда на величину базы). Если значения ряда из окрестности данной точки входят с одним и тем же весом, то такая операция сглаживания ряда называется методом простого скользящего среднего.
При использовании данного метода большое значение имеет выбор базы. Если, например, имеются данные о ежемесячных объемах продаж и в качестве базы выбрано 12 точек (12 месяцев), то тренд может оказаться излишне сглаженным (слишком усредненным). Если в качестве базы выбраны три точки, то излишнее влияние могут оказывать случайные выбросы. При выборе в качестве базы одной точки эффекта сглаживания нет совсем. В этом случае предполагается, что значение характеристики ряда в последующий период будет таким же, что и в текущем периоде, поэтому такой подход к прогнозированию, когда база равна единице, называется наивным. В качестве индикаторов выбора оптимальной базы следует использовать графический вид ряда, по которому можно первоначально судить о его динамике и зашумленности, а также показатели МАЕ, MSE и МАРЕ |6|.
Решение в MS Excel
Метод простого скользящего среднего легко реализуется в MS Excel. Для этого достаточно воспользоваться функцией СРЗНАЧ, указав в качестве аргументов массив предыдущих значений ряда (например, если база равна трем точкам, то в качестве аргумента функции будет выступать массив из трех ячеек), и затем скопировать формулу в нижеследующие ячейки. Затем нужно определить разности значений исходного и сглаженного рядов в каждой точке, после чего найти показатели МАЕ, MSE и МАРЕ.
Решение в R
Сглаживание временного ряда методом скользящего среднего в R осуществляется с помощью функции filter (…). Например, команда.
v = filter (w, sides = 2, гер (1/3, 3)).
строит сглаженный временной ряд v на основе исходного ряда w, и элементы сглаженного ряда определяются через среднее значение элементов исходного ряда в симметричной двусторонней окрестности (sides = 2) с базой 3:
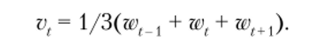
Это простейший метод сглаживания временного ряда, довольно часто используемый на практике. Как правило, это метод используется однократно. Но иногда (при очень зашумленных данных) процедура сглаживания используется несколько раз: сглаживается исходный ряд, затем — сглаженный ряд и г. д.
Недостатки этого метода очевидны. Во-первых, значения ряда за предыдущие периоды, используемые для прогнозирования, имеют одинаковый вес. Но на последующее развитие процесса текущие его состояния могут оказывать более сильное влияние, чем относительно более ранние. Во-вторых, для применения этого метода, как правило, требуется довольно большой массив данных (сотни наблюдений).
2. Другим, более качественным методом сглаживания и прогнозирования, избавленным от указанных недостатков, является метод экспоненциального сглаживания временного ряда. Эта процедура использует веса, убывающие по геометрическому или экспоненциальному закону. Экспоненциальное сглаживание — это на сегодняшний день наиболее популярная серия методов прогнозирования временных рядов. Впервые серия этих методов была разработана и использована для решения военных, а затем и экономических задач в 1940—1950;е гг.
Существует несколько видов экспоненциального сглаживания, реализованных в статистических пакетах. Самая простая процедура называется простым {simple) экспоненциальным сглаживанием. Она предполагает, что ряд не содержит ни тренда, ни сезонной составляющей. Если наблюдается тренд, но нет сезонной составляющей, используется метод Холта {Holt method). Если ряд содержит и сезонную компоненту, применяется метод Винтерса {Winters method). Разработаны и другие процедуры экспоненциального сглаживания, но названные три метода применяются наиболее часто, и для большинства практических случаев они оказываются вполне достаточными для построения качественного прогноза.
Модель простого экспоненциального сглаживания представляется в следующем виде: 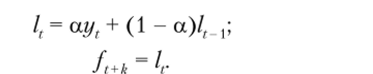
Здесь у( — значение ряда в момент времени t fl+k — прогнозное значение yt+k /, — переменная, называемая уровнем {level) ряда; а — постоянная сглаживания {smoothing constant), принимающая значения от 0 до 1.
В данной модели текущий уровень ряда представляется как взвешенное среднее текущего значения ряда г/, (взятого с весом а) и предыдущего уровня ряда lt_x (взятого с весом 1 — а), а прогнозное значение на k периодов вперед определяется по последней оценке уровня ряда (прогнозное значение, следовательно, будет одним и тем же для любого k > 1).
Учитывая что для момента времени t ошибка прогноза е, определяется как е,= yt — ft = yt — lt_v модель простого экспоненциального сглаживания может быть переписана как lt = lt_{ + asr Из этого следует, что текущее значения уровня ряда определяется на основе предыдущего значения уровня ряда с учетом текущего значения ошибки прогноза (т.е. если предыдущий прогноз был завышенным (г, 0) текущее значение уровня ряда увеличивается). Величина корректировки зависит от значения а: чем больше а, тем значительнее корректировка, т. е. тем чувствительнее прогноз к изменениям ряда.
Более наглядно эффект влияния величины постоянной сглаживания проявляется, если переписать исходную модель, рекурсивно подставляя в нее значения lr_vl{_2 и т. д. В результате получается следующее выражение (читателю рекомендуется проверить это самостоятельно):
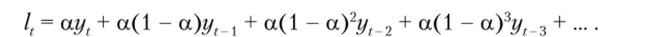
Такой вид модели отчетливо демонстрирует, что текущий прогноз значения ряда зависит от всех предыдущих значений ряда, но берущихся с уменьшающимися весами. Если значение, а близко к нулю, а значение 1 — а, соответственно, близко к единице, то весовые коэффициенты перед предыдущими значениями ряда уменьшаются незначительно, т. е. предыдущие значения ряда продолжают оказывать довольно сильное влияние на прогнозируемое значение; в результате сглаживание (усреднение) ряда получается довольно сильным.
Если значение, а близко к единице, то весовые коэффициенты перед предыдущими значениями ряда уменьшаются очень быстро, т. е. лишь ближайшие значения ряда оказывают наиболее заметное влияние на прогнозируемое значение; в результате прогнозные значения весьма заметно реагируют на изменения значений ряда. В пределе, если, а точно равно единице, то предыдущие наблюдения полностью игнорируются. Если, а точно равно нулю, то игнорируются текущие наблюдения.
Какое же значение следует выбрать при использовании этой модели? Некоторые специалисты рекомендуют значения, а = 0,1, или, а = 0,2, или, во всяком случае, не больше 0,3 [29]. Другие исследования показывают, что значения, а > 0,3 для некоторых рядов обеспечивают лучший прогноз, чем меньшие значения а. Поэтому лучше оценить качество прогноза для нескольких различных значений а. Многие статистические пакеты включают в себя оптимизационные процедуры для подбора такого значения а, которое минимизирует значение MSE или МАРЕ. Простейшая из таких процедур (поиск по сетке) работает следующим образом: возможные значения параметра, а разбиваются сеткой с определенным шагом. Например, рассматривается сетка значений от, а = 0,1 до, а = 0,9 с шагом 0,1. Затем выбирается а, для которого значение MSE или МАРЕ является минимальным. Существуют и более сложные процедуры подбора оптимального а. Однако, как уже неоднократно подчеркивалось, минимизация данных показателей может свидетельствовать о хорошем приближении к исходным данным, но необязательно гарантирует наилучший прогноз будущих значений ряда.
Формула простого экспоненциального сглаживания показывает, что для вычисления первого уровня ряда (/,) нужно знать значение /0, но /() неизвестно. Выбор начального значения (initial value) уровня ряда (1{) называется инициализацией. В зависимости от выбора параметра, а (особенно, если, а близко к нулю) начальное значение сглаженного процесса может оказать существенное воздействие на прогноз для многих последующих наблюдений. Обычно начальное значение 1Х принимается равным значению уу В статистических пакетах можно задавать и любые другие начальные значения уровня. Как и в других рекомендациях по применению экспоненциального сглаживания, рекомендуется брать начальное значение, дающее наилучший прогноз. Статистические пакеты включают в себя и специальные процедуры автоматического поиска оптимального начального значения. Влияние эффекта инициализации значительно уменьшается с длиной ряда и становится некритичным при большом числе наблюдений.
Покажем использование процедуры простого экспоненциального сглаживания в SPSS.
Решение в SPSS
Имеются данные (42 наблюдения), характеризующие ежеквартальные объемы продаж (тыс. ден. ед.) некоторой компании (представлены как исходный ряд на рис. 10.12). Эти данные введены в качестве переменной «продажи» в SPSS. В меню Analyze (анализ) программы SPSS выбирается опция Типе Senes (временные ряды), затем — Exponential Smoothing (экспоненциальное сглаживание). В появившемся диалоговом окне переменная «продажи» переносится в поле Variables (переменные). В разделе Model (модель) отмечается Simple (простое сглаживание).
Параметры сглаживания устанавливаются в диалоговом окне Exponential Smoothing: Parameters (вызывается нажатием на кнопку Parameters). В разделе.

Рис. 10.12. Исходный и сглаженный ряды при, а = 0,2 (выдача программы SPSS).
General {Alpha) в поле Value по умолчанию указывается значение, а = 0,1. Если требуется подбор оптимального значения а, в этом разделе нужно выбрать параметр Grid Search (поиск по сетке) и указываются параметры метода поиска по сетке: Start (начальное значение a), Stop (конечное значение а) и Step (шаг). Для данного примера в поле Value указываем значение, а = 0,2. После завершения установки параметров сглаживания нужно нажать на кнопку Continue (продолжить), чтобы вернуться в окно Exponential Smoothing. Если требуется построить прогноз на несколько периодов вперед, необходимо нажать на кнопку Save, после чего в разделе Predict Cases выбрать параметр Predict through (прогнозировать до) и в иоле Observation (наблюдения) указать последний период, для которого строится прогноз. Для данного примера (42 наблюдения) указываем значение 46 (т.е. прогноз должен строиться на четыре квартала вперед). Если параметр Predict through не выбирается, то прогнозные значения ряда строятся для имеющегося диапазона наблюдений (t = 1,…, п).
После нажатия на кнопку ОК в окне Exponential Smoothing в области данных SPSS появляются две новые переменные, значения которых соответствуют прогнозным значения ряда и ошибкам прогноза. Результаты сглаживания ряда (исходные и прогнозные значения) представлены на рис. 10.12.
Визуальное сравнение показывает, что значения сглаженного ряда (т.е. прогнозные значения) не очень хорошо соответствуют исходному распределению данных, но если рассматривать «зигзаги» в исходном ряду лишь как случайный шум, то, очевидно, и не следует стремиться к близкому повторению этого шума (т.е. стремиться к модели, слишком чувствительной к случайным колебаниям).
Для данной модели средняя абсолютная процентная ошибка (МАРЕ) составляет около 8%. Попытаться улучшить этот результат можно, запустив процедуры поиска оптимального значения параметра а. Соответствующая процедура программы SPSS даст для, а результат, близкий к 0,9. Однако в этом случае сглаженный ряд хотя и обеспечивает меньшее значение ошибки (МАРЕ = 5,9), вряд ли может считаться лучшей прогностической моделью, так как прогнозные значения получаются очень сильно зависящими от ближайшего предыдущего периода, т. е. модель слишком чувствительна к шуму (рис. 10.13). Этот пример показывает, что технически оптимальное значение, а не всегда обеспечивает наилучшую прогностическую модель.
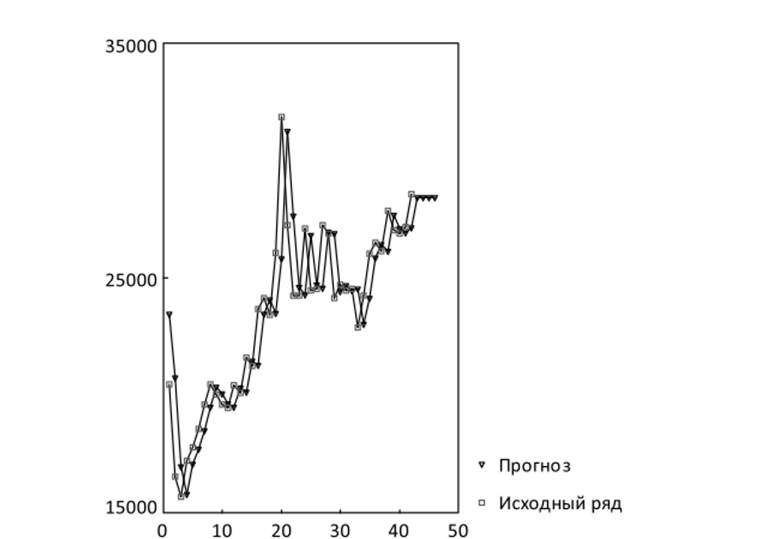
Рис. 10.13. Исходный и сглаженный ряды при, а = 0,9 (выдача программы SPSS).
3. Если временной ряд содержит тренд, для сглаживания ряда должна использоваться модель Холта:

По сравнению с моделью простого экспоненциального сглаживания здесь используются два новых параметра: т( — значение тренда в момент времени t у — постоянная сглаживания для тренда.
Все рассуждения, приведенные ранее для константы а, верны и для константы у. Эта константа определяет, насколько модель чувствительна к изменениям тренда. При небольших значениях у модель менее чувствительна (более медленно реагирует на изменения тренда), и наоборот. Очевидно, что при использовании данной модели вместо выбора (или подбора) значений одной константы в модели сглаживания требуется подбирать значения двух констант. Специалисты советуют устанавливать значения, а и у равными друг другу и небольшими (0,1 или 0,2) либо использовать оптимизационные процедуры для подбора этих параметров [29].
Работа с моделью Холта в статистических пакетах аналогична работе с моделью простого экспоненциального сглаживания, за исключением того, что в соответствующих разделах диалоговых окон выбирается режим Holt. Постоянная сглаживания тренда обозначена в SPSS как Gamma, а в R — как beta.
Пример 10.4. Для примера вновь обратимся к временному ряду, отражающему динамику фондового индекса (см. рис. 10.4). Если сглаживать этот ряд на основе модели простого экспоненциального сглаживания (с, а = 0,2), получим результат, представленный на рис. 10.14 (ряд 2) (МЛРЕ= 5,3). На этом же рисунке для сравнения приведен результат применения модели Холта с параметрами, а = у = 0,2 и МАРЕ = 3,9 (ряд 3). Для данного примера модель Холта обеспечивает заметно лучшую точность прогноза и улавливает линейный тренд.

Рис. 10.14. Исходный ряд (ряд 1), модель простого экспоненциального сглаживания (ряд 2), модель Холта (ряд 3) (выдача программы SPSS).
Процедура поиска оптимальных значений для параметров модели Холта предлагает, а = 1 и у = 0, что еще сильнее снижает среднюю абсолютную процентную ошибку (МАРЕ = 2,3). Исходный и сглаженный ряды приведены на рис. 10.15. Обращаем внимание читателя на то, что такой результат получен для данного конкретного ряда. Для другого набора данных оптимальные значения, а и у могут быть другими, т. е. они необязательно должны принимать пограничные значения.

Рис. 10.15. Исходные (ряд 1) и прогнозные (ряд 2) значения ряда при оптимальных параметрах модели Холта (выдача программы SPSS).
Теперь рассмотрим модель Винтерса — модель экспоненциального сглаживания, учитывающую сезонность. Как обсуждалось в параграфе 10.1, сезонная составляющая временного ряда представляет собой некоторые регулярные паттерны, повторяющиеся с определенной периодичностью.
К примеру, объемы продаж елочных игрушек могут резко возрастать в канун новогодних праздников с ежегодной повторяемостью.
Существует два основных подхода к прогнозированию с учетом сезонной составляющей. Первый подход учитывает сезонность непосредственно (модель Винтерса представляет данный подход). Второй подход предполагает первоначальное исключение сезонной составляющей из ряда, затем построение прогноза и последующую корректировку прогноза с учетом сезонной составляющей (этот подход рассматривается ниже).
Модель Винтерса является усложнением модели Холта и представляется в следующем виде:
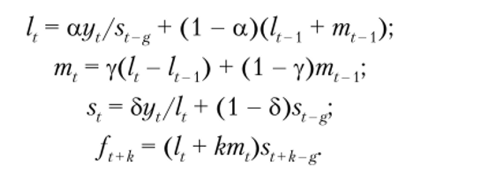
По сравнению с моделью Холта в модели Винтерса используются несколько новых параметров: st — значение сезонной компоненты в момент времени V, 5 — постоянная сглаживания для сезонной компоненты, g — сезонный лаг, который соответствует временному периоду, через который наблюдается сезонное повторение значения ряда (например, g = 4 для данных, фиксируемых каждый месяц, с периодом повторения через четыре месяца).
Константа 8 определяет чувствительность модели к изменениям сезонной составляющей[1]. Чем меньше эта величина, тем менее чувствительной будет модель к сезонным паттернам. Рекомендуемые специалистами типовые значения параметров модели: а = у = 0,2,5 = 0,5 [29]. Но, как и в случае ранее рассмотренных моделей сглаживания, можно использовать специальные статистические процедуры определения оптимальных параметров модели.
Решение в SPSS
Работа с моделью Винтерса в пакете SPSS осуществляется аналогично работе с моделью простого экспоненциального сглаживания и моделью Холта. Но для применения модели Винтерса данные предварительно нужно определить как значения временного ряда. Для этого из меню Data (данные) нужно выбрать опцию Define Dates (определить временные периоды). В разделе Cases Are можно выбрать возможные временные составляющие ряда (например, изменение по годам {Years), изменение по годам и кварталам {Years, quarters), изменение по годам и месяцам {Years, months) и т. д.). Для рассматриваемого гипотетического ряда реальные временные составляющие неизвестны, но в ряду очевидно наблюдается периодичность с периодом 4. Поэтому необходимо определить этот период. Для данного случая можно выбрать, например, изменение по годам и кварталам {Years, quarters). Это будет означать, что повторяющий паттерн наблюдается ежегодно с минимальным значением в первом квартале и максимальным значением в третьем квартале. После определения временной составляющей ряда в меню Analyze (анализ) выбирается опция Time Series (временные ряды), затем — Exponential Smoothing (экспоненциальное сглаживание) и в соответствующем окне — параметр Winters. Дальнейшая последовательность действий полностью аналогична работе с моделью Холта.
Пример 10.5. Продемонстрируем работу рассмотренной процедуры на примере ряда, представленного па рис. 10.8.
Па графике наблюдается очевидная сезонность с лагом 4. Коррелограмма анализируемого ряда приведена па рис. 10.16. Она показывает, что ряд действительно имеет четко выраженную сезонную составляющую с периодом, равным четырем.

Рис. 10.16. Коррелограмма временного ряда с сезонной составляющей (выдача программы SPSS)
Ряд, сглаженный по методу Винтерса, с прогнозными значениями на 10 следующих периодов приведен на рис. 10.17. Значения оптимальных параметров модели, полученные в результате автоматического определения (критерий оптимальности — минимум MSE), следующие: а = 0,66; 5 = 1,0; у = 0. При таких параметрах MSE = 0,84, МАЕ = 0,67, МАРЕ = 3,3, что является индикатором хорошего приближения модели к эмпирическим данным. Модель достаточно чувствительна к изменениям уровня ряда и быстро реагирует на них (а = 0,66), нечувствительна к изменениям тренда (у = 0), что необязательно означает его отсутствие, и максимально чувствительна к сезонным паттернам (5=1,0).
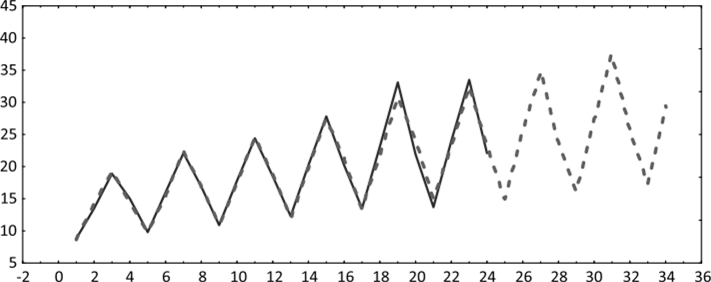
Рис. 10.17. Исходный ряд и ряд, сглаженный по методу Винтерса, с прогнозными значениями на 10 следующих периодов (выдача программы SPSS)
Если в качестве критерия оптимальности выбрать минимум МАРЕ, то можно получить даже несколько лучшие показатели адекватности модели: MSE = = 0,82, МАЕ = 0,54, МАРЕ = 2,6. При этом параметры модели принимают следующие значения: а = 0; 8 = 0,38; у = 0,09, т. е. данная модель не чувствительна к изменению уровня ряда, но реагирует на изменение сезонной компоненты и отчасти на изменения тренда. В то же время полученный сглаженный ряд визуально практически не отличается от показанного на рис. 10.17, поэтому график ряда, сглаженного по методу Винтерса с этими параметрами, мы не приводим.
Решение в R
Модель Холта — Винтерса в R реализуется с помощью функции IIoltWinters (…). Параметры функции, задаваемые по умочанию:
HoltWinters (tl, alpha = NULL, beta = NULL, gamma = NULL, seasonal = c («additive», «multiplicative»), start. periods = 2, l. start = NULL, b. start = NULL, s. start = NULL, optim. start = c (alpha = 0.3, beta = 0.1, gamma = 0.1)).
В этом случае параметры сглаживания устанавливаются автоматически.
Пример 10.6. Покажем действие этой функции на рассматриваемом примере (см. рис. 10.8). Допустим, задан временной ряд tv Тогда сглаженный ряд с автоматическим определением параметра alpha, но заданными пользователем параметрами beta = 0 и gamma = 0 задается как.
rl = HoltWintersftl, beta = 0, gamma = 0).
Прогнозные значения ряда на следующие четыре периода с повторяемостью 4 определяются с помощью команды.
r2 = predict (rl, n. ahead = 4*4).
Графически исходный ряд и прогнозные значения выводятся при выполнении функции ts. plot (tl, г2) и представлены на рис. 10.18.
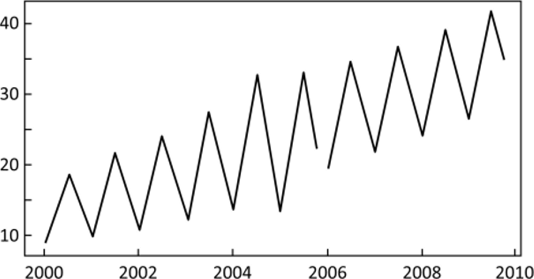
Рис. 10.18. Исходный ряд и прогноз на будущие периоды (выдача программы R).
На этом примере мы видим, что модель Винтерса хорошо отслеживает сезонные составляющие и демонстрирует возможности прогнозировать сезонные изменения в будущем. Для сравнения на рис. 10.19 приведены результаты применения модели простого экспоненциального сглаживания и сглаживания, но Холту. Очевидно, что эти две модели не могут считаться адекватными для анализа рассматриваемого временного ряда.

Рис. 10.19. Исходный ряд (ряд 1), модель Холта (ряд 2), модель простого экспоненциального сглаживания (ряд 3) (результаты получены с помощью программы R и представлены в MS Excel).
Помимо трех моделей экспоненциального сглаживания, которые рассмотрены в данном параграфе, в статистических пакетах реализованы и другие (более сложные) модели сглаживания временных рядов, например модель экспоненциального тренда (exponential trend) и модель демпфированного (затухающего) тренда (damped trend), которые работают как без учета, так и с учетом сезонной составляющей. Как правило, точность прогноза, полученного с их помощью, лишь незначительно улучшается по сравнению с применением рассмотренных в данном параграфе моделей. Порядок работы с моделями экспоненциального и затухающего тренда принципиально не отличается от работы с рассмотренными моделями сглаживания.
- [1] В SPSS этот параметр обозначен как Delta, а в R — как gamma.