Подготовка обучающей и тестовой выборки

Первым шагом в подготовке выборок был отбор переводных эквивалентов, к которым затем подбирались контексты. Чтобы сделать этот «словарь» более репрезентативным, переводные эквиваленты выбирались случайно таким образом, чтобы распределение их частот соответствовало распределению частот слов в параллельном корпусе. Кроме того, необходимо было установить такое же соответствие с распределением частот… Читать ещё >
Подготовка обучающей и тестовой выборки (реферат, курсовая, диплом, контрольная)
Как уже было сказано, основной задачей эксперимента является упорядочивание иллюстрирующих контекстов в соответствии с допустимостью их использования в качестве материала для иллюстративного блока. Для решения этой задачи мы предлагаем ранжирующий классификатор — алгоритм, который по обучающей выборке приписывает элементам тестовой выборки оценки в заданном диапазоне таким образом, что элементы могут быть затем упорядочены по значению этой оценки. Цель ранжирующей модели — наилучшим образом (в некотором смысле) приблизить и обобщить способ ранжирования в обучающей выборке на новые данные.
Для обучения ранжирующего классификатора были размечены обучающий и тестовый наборы контекстов.
Первым шагом в подготовке выборок был отбор переводных эквивалентов, к которым затем подбирались контексты. Чтобы сделать этот «словарь» более репрезентативным, переводные эквиваленты выбирались случайно таким образом, чтобы распределение их частот соответствовало распределению частот слов в параллельном корпусе. Кроме того, необходимо было установить такое же соответствие с распределением частот запросов к словарю. Было замечено, что количество запросов на английском языке в значительной степени коррелирует с частотой соответствующих слов в корпусе [Antonova, Misyurev 2014], поэтому можно полагаться только на корпусную статистику. Также в выборку не включалось сто самых частых английских слов.
Для каждой пары переводных эквивалентов в словаре из параллельного корпуса извлекаются все возможные контексты (биграммы), как описано в предыдущем разделе. Случайная выборка из полученного множества контекстов могла бы быть ненадёжной, поскольку в ней сложно было бы обеспечить баланс между положительными и отрицательными примерами. Поэтому каждому контексту приписывается вес по эмпирической формуле, которая соответствует произведению прямой и обратной вероятности перевода.
где.

— частота выравнивания контекста на входном языке в контекст на выходном языке в параллельном корпусе;
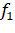
— частота контекста на входном языке в том же параллельном корпусе;
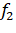
— частота контекста на выходном языке в том же параллельном корпусе.
Затем для каждой пары переводных эквивалентов выбирается несколько (от одного до трёх в зависимости от общего числа кандидатов) с наибольшим весом. Таким образом была получена выборка объёмом 700 словосочетаний.
Разметка производилась вручную по пятибалльной шкале от 1 (неприемлемый контекст) до 5 (идеально подходящий контекст). В таблице приведены неформальные критерии, использованные при выставлении оценки. Стоит напомнить, что каждый параллельный контекст состоит из двух частей — входной и выходной. В качестве эксперимента примеры размечались в двух режимах — сначала оценка приписывалась обеим частям, затем каждой по отдельности. При составлении критериев использовался опыт группы аналитиков отдела машинного перевода компании «Яндекс».
3. Принципы разметки контекстов-кандидатов.
Оценка. | разметка обеих частей. | разметка одной части. | пример | |
Обе части бессмысленны и грамматически неправильны; части не являются переводными эквивалентами. | Фраза бессмысленна и грамматически некорректна. | *pickled > *маринованная. | ||
Одна из частей соответствует оценке один по принципам разметки одной части примера; обе или одна из фраз грамматически некорректна. | Фраза грамматически некорректна; фраза не является переводным эквивалентом. | caribbean > *караибское. | ||
Обе части грамматически корректны, но не отражают особенностей значения / употребления / перевода ключа. | Фраза грамматически корректна, но не отражает особенностей значения / употребления / перевода ключа. | *его > *his. | ||
Обе части грамматически корректны и частично иллюстрируют особенности значения / употребления / перевода ключа. | Фраза грамматически корректна и частично иллюстрирует особенности значения / употребления / перевода ключа. | quit the company > покинуть компанию. | ||
Идеально подходящий контекст. | Идеально подходящий контекст. | ball lightning > шаровая молния. | ||
Как было сказано выше, контексты извлекались из корпуса для всех соответствий «английская лексема — русская лексема», полученных из машинного словаря. Машинный словарь в свою очередь содержит некоторое количество «шумных» (ошибочных) переводов: например, из недословных переводов можно извлечь перевод «beautiful — красота». Они были удалены из выборки после разметки. В результате размеченный набор составил более 600 примеров. Результаты разметки каждой из частей по отдельности приведены на рисунке 9.

Рисунок 9. Результаты разметки контекстов по пятибалльной шкале: тёмным отмечены английские контексты, светлым — русские.