Проверка гипотез, связанных с кросс-табуляцией

Итак, мы умеем строить таблицы сопряженности для двух переменных (вопросов). В SPSS есть возможность строить таблицы большей размерности, т. е. получать распределения значений зависимой переменной по различным сочетаниям категорий нескольких независимых переменных, например изучить зависимость продолжительности пребывания клиентов в фитнес-центре от типа клубной карты, пола и возраста респондента. Читать ещё >
Проверка гипотез, связанных с кросс-табуляцией (реферат, курсовая, диплом, контрольная)
Проверка гипотезы о существовании связи. При анализе таблиц кросс-табуляции постоянно возникают вопросы о том, достаточно ли обнаруженных различий в распределении ответов в разных столбцах таблицы, чтобы сделать вывод о существовании статистически значимой связи. Имеется ряд статистических критериев, позволяющих дать ответ на данный вопрос и другие аналогичные вопросы.
Основная идея, лежащая в основе этих критериев, — сравнить fо — фактическое число респондентов, отнесенных к каждой клетке таблицы, сfе — ожидаемым числом таких респондентов в предположении независимости строк и столбцов таблицы.
Формула для расчета ожидаемого числа респондентов в клетке таблицы имеет вид:
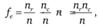 (12.10).
(12.10).
где nr — число респондентов во всех клетках данной строки таблицы кросс-табуляции; nс — число респондентов во всех клетках данного столбца таблицы кросс-табуляции; n — число респондентов во всех клетках таблицы кросстабуляции.
Смысл формулы (12.10) достаточно прост. Примем в качестве нулевой гипотезы, что вопрос, ответы на который расположены по столбцам таблицы, и вопрос, ответы на которые образуют строки таблицы, в действительности независимы. Это означало бы, что, если бы мы опросили не выборку респондентов, а всех представителей исследуемой совокупности, распределение ответов в каждом столбце было бы одинаковым и, следовательно, таким же, как распределение ответов на этот вопрос среди всех опрошенных.
Тогда долю наблюдений, приходящихся на каждую клетку таблицы, можно было бы подсчитать, перемножив долю представителей исследуемой совокупности, приходящуюся на столбец, и их долю, приходящуюся на строку таблицы.
Выборочными оценками этих долей служат дроби 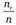 и
и 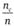
Умножив полученное произведение на размер выборки п, мы получаем искомое число респондентов, которые относились бы к клетке таблицы в случае, если бы нулевая гипотеза была верна и случайные колебания, связанные с конкретной выборкой, отсутствовали.
Наиболее часто используемый статистический критерий для проверки описанной выше нулевой гипотезы — критерий ???2. Он рассчитывается по формуле:
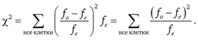 (12.11).
(12.11).
Смысл этого критерия таков. Он представляет собой взвешенную сумму квадратов относительных различий между фактической и ожидаемой наполненностью каждой клетки таблицы. Весовые коэффициенты представляют собой ожидаемую наполненность клеток таблицы. В сумме они составляют общее число респондентов п.
Отметим, что величину (fo — fe) принято называть остатками (residuals), а величину:
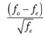 - стандартизованными остатками (standardized residuals).
- стандартизованными остатками (standardized residuals).
Поэтому можно также сказать, что критерий ?2 представляет собой сумму квадратов стандартизованных остатков.
Зная стандартизованный остаток, можно судить о значимости различий между ожидаемым и фактическим числом респондентов, отнесенных к данной клетке таблицы. Предположим, что в клетке оказалось больше респондентов, чем ожидалось. Если при этом стандартизованный остаток превысил 1,96, то вероятность, что превышение в числе респондентов случайно, менее 0,025; а если он превысил 2,6, эта вероятность мене 0,005.
Заметим, что иногда используется другая формула для расчета нормированных остатков. Результаты расчета по ней принято называть уточненными нормированными остатками (adjusted standardized residuals):
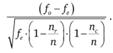 (12.12).
(12.12).
Проиллюстрируем с помощью табл. 12.19 и 12.20 расчет коэффициента ???2 на данных табл. 12.12.
Таблица 12.19. Расчет ожидаемого числа респондентов в клетках таблицы кросс-табуляции для проверки значимости связи между продолжительностью пребывания в фитнес-центре и возрастом
Продолжительность пребывания в клубе | Возраст | Все опрошенные | |
26−35 лет | 36−46 лет | ||
менее 2 ч. | 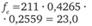 | 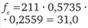 |  |
2−2,5 ч. | 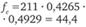 | 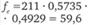 | 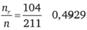 |
более 2,5 ч. | 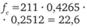 | 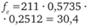 | 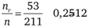 |
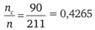 | 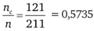 | ||
Таблица 12.20. Расчет коэффициента ?2 для проверки значимости связи между продолжительностью пребывания в фитнес-центре и возрастом.
Продолжительность пребывания в клубе | Возраст | |
26−35 лет | 36−46 лет | |
менее 2 ч. | 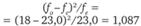 | 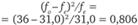 |
2−2,5 ч. | 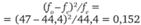 | 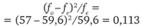 |
более 2,5 ч. | 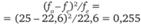 | 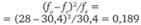 |
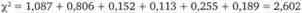 | ||
Распределение ?2, как и нормальное распределение (см. рис. 12.13), табулировано. Форму распределения ?2 иллюстрирует рис. 12.14. Существует целое семейство кривых с разным числом степеней свободы (df). Чем оно больше, тем более симметрична кривая. В пределе это распределение стремится к нормальному. Для таблиц кросс-табуляции число степеней свободы рассчитывается по формуле:
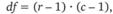 (12.13).
(12.13).
где r и с — число строк и число столбцов таблицы соответственно.
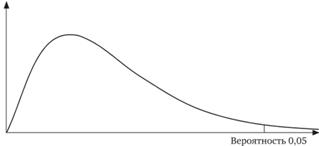
Рис. 12.13. Проверка гипотезы с помощью распределения хи-квадрат В данном случае таблица содержит две строки и три столбца, т. е. распределение характеризуется двумя степенями свободы.
Аналогично тому, как использовалась кривая стандартизованного нормального распределения (см. рис. 12.13), здесь по таблицам, с помощью пакета SPSS (меню Analyze > Descriptive Statistics > Cross Tabulation) или функции CHIDIST (14.201,2) Microsoft Excel можно обнаружить, что вероятность случайного появления числа, равного или большего 2,602, равна 0,272 259. Это существенно больше избранного нами порога 0,05, соответствующего доверительной вероятности 0,95. Следовательно, нулевая гипотеза об отсутствии связи между продолжительностью пребывания в клубе и возрастом респондентов не может быть отвергнута, т. е. данные опроса противоречат альтернативной гипотезе о наличии такой связи.
Проверять гипотезы о связи вопросов по критерию ?2 можно, если ни в одной клетке ожидаемое число респондентов fe не меньше пяти. Более того, если есть клетки, где это число меньше 10, оценки становятся очень грубыми.
Итак, мы умеем строить таблицы сопряженности для двух переменных (вопросов). В SPSS есть возможность строить таблицы большей размерности, т. е. получать распределения значений зависимой переменной по различным сочетаниям категорий нескольких независимых переменных, например изучить зависимость продолжительности пребывания клиентов в фитнес-центре от типа клубной карты, пола и возраста респондента.
Кроме того, мы научились оценивать по критерию ?2 факт существования связи между двумя переменными, по которым построены таблица. При этом помним, что ожидаемое число респондентов (fe) в каждой клетке таблицы, которое рассчитывается при условии независимости ее строк и столбцов, не должно быть меньше пяти, а еще лучше, если оно будет не меньше десяти. Для трехуровневых и более сложных таблиц сразу рассчитать значение критерия ?2 нельзя. Оценить значимость существования связи для многоуровневой таблицы можно, построив новую переменную, категории которой представляют столбцы такой таблицы. Теперь можно рассчитать таблицу сопряженности для двух переменных — зависимой и новой — и оценить по критерию ?2 значимость связи между ними.
Меры силы связи. Зная ?2, можно не только проверить гипотезу о наличии связи между включенными в таблицу кросс-табуляции вопросами анкеты, но и ответить на вопрос, насколько эта связь сильна.
Так, для таблиц из двух строк и двух столбцов удобен фи-коэффициент Фишера (phi coefficient):
Если статистической связи между вопросами нет, этот коэффициент равен 0, а при наибольшей зависимости (если, зная ответ респондента на один из вопросов, можно однозначно сказать, как он ответил на другой) он равен 1.
Для таблиц с произвольным числом строк и столбцов используется коэффициент сопряженности признаков Пирсона (contingency coefficient):
При отсутствии связи этот коэффициент тоже равен нулю. А вот единицы он не достигает ни при каких обстоятельствах. Поэтому сравнивать между собой силу разных связей он позволяет лишь для таблиц, у которых одинаковое число строк и столбцов.
Существуют и другие меры связи между вопросами анкеты, обсуждать которые мы не будем, так как они используются значительно реже.
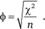 (12.14).
(12.14).
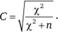 (12.15).
(12.15).
Таким образом, работу с таблицами кросс-табуляции в маркетинговых исследованиях можно представить в виде последовательности, состоящей из трех шагов:
- 1) проверить с помощью критерия ?2, что данные не противоречат существованию связи между вопросами (т.е. что нулевая гипотеза об отсутствии связи между вопросами при выбранной доверительной вероятности отвергается);
- 2) оценить силу связи с помощью коэффициента Фишера, коэффициента сопряженности признаков Пирсона и др.;
- 3) если связь оказалась статистически значимой и достаточно сильной, проинтерпретировать ее, рассчитав процентное распределение ответов на вопрос, являющийся зависимой переменной (Y), при каждом значении независимой переменной (X).