Деревья принятия решений

Мы выбирали разделяющую переменную путем своих логических рассуждений, алгоритм же производит выбор путем вычисления информационного выигрыша — количества информации, которое содержится в делении множества на два поднабора. Он рассчитывается следующим образом: В рассмотренном примере мы быстро нашли переменную, оптимальную для разбиения, однако в больших объемах данных такую переменную найти… Читать ещё >
Деревья принятия решений (реферат, курсовая, диплом, контрольная)
Использование энтропии в деревьях принятия решений
Одним из простейших методов машинного обучения является метод, основанный на деревьях решений. Этот метод очень удобен в решении задач классификации.
Прежде чем углубляться в техническую реализацию данного метода, введем понятие энтропии. В теории информации энтропией называется мера неоднородности множества (в нашем случае — данных), т. е. чем менее однородно множество, тем выше энтропия. Допустим, если у нас на компьютере в папке «Фильмы» есть только фантастические фильмы, т. е. множество полностью однородно, это означает, что энтропия равна нулю. Энтропию можно вычислить с помощью следующей формулы (энтропия Шеннона):

где Pi — частота вхождения элемента (например, вероятность того, что случайно выбранный фильм будет именного этого жанра). В свою очередь, она вычисляется по следующей формуле:
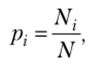
где N — общее количество элементов (в нашем примере — фильмов); Nj — количество элементов определенного класса (например, фильмов одного и того же жанра).
Наша цель (цель обучения) — разбить элементы на группы так, чтобы энтропия уменьшилась, т. е. группы были более однородными[1]. Рассмотрим это утверждение на следующем примере.
Дано множество фильмов разных жанров. Известно количество комедийных актеров и имя режиссера (табл. 5.1).
Таблица 5.1
Данные о фильмах.
Жанр | Количество комедийных актеров. | Имя режиссера. |
Драма. | Дастин Хоффман. | |
Драма. | Вуди Аллен. | |
Комедия. | Дастин Хоффман. | |
Мелодрама. | Вуди Аллен. | |
Драма. | Дастин Хоффман. |
Необходимо составить дерево решений для этого множества.
Первое, что необходимо сделать, — определить, какой признак мы возьмем для первого разделения на группы. Для того чтобы сделать выбор, мы должны рассмотреть оба варианта разбиения (но обоим переменным: по количеству актеров комедийного жанра и по имени режиссера). При разбиении по имени режиссера получим результаты, показанные в табл. 5.2.
Таблица 5.2
Разбиение жанров фильмов по имени режиссера.
Вуди Аллен. | Дастин Хоффман. |
Драма. | Драма. |
Комедия. | Мелодрама. |
Драма. |
Результат нас не устраивает, поскольку данные все еще неоднородны (перемешаны). Попробуем разбить фильмы по количеству комедийных актеров (табл. 5.3).
Таблица 53
Разбиение жанров фильмов по количеству комедийных актеров.
Количество комедийных актеров больше или равно 5. | Количество комедийных актеров меньше 5. |
Комедия. | Драма. |
Мелодрама. | Драма. |
Драма. |
Как видно из табл. 5.3, данные стали более однородными, чем в табл. 5.2, стало быть, и результат стал более понятным. Назовем данные в левом столбце поднабором 1, а в правом столбце — поднабором 2. В поднабор 2 попали фильмы жанра «Драма» из исходных данных. Энтропия поднабора 2 равна нулю.
В рассмотренном примере мы быстро нашли переменную, оптимальную для разбиения, однако в больших объемах данных такую переменную найти крайне сложно, поэтому для разбиения используется энтропия, о которой говорилось ранее в этой части.
Мы выбирали разделяющую переменную путем своих логических рассуждений, алгоритм же производит выбор путем вычисления информационного выигрыша — количества информации, которое содержится в делении множества на два поднабора. Он рассчитывается следующим образом:

где б'0 — начальная энтропия; б, — энтропия поднабора 1; S2 — энтропия поднабора 2; JV, iV2 — размеры поднаборов 1 и 2 соответственно; N — размер исходного поднабора.
После выбора разделяющей переменной создадим первый (корневой) узел (рис. 5.4).

Рис. 5.4. Корень дерева решений для множества данных о фильмах.
Мы проделали первый шаг в алгоритме дерева решений. Следующим шагом будет разделение ветви «Нет» тем же способом, поскольку данные в ней еще не однородны. В данном случае лучшей переменной для разделения будет имя режиссера. Ветвь «Да» разделить уже невозможно, в ней всего один узел, который и становится листом. Для построения полного дерева необходимо продолжать разделение тех ветвей, которые еще можно разделить. Алгоритм закончит свою работу тогда, когда информационный выигрыш перестанет увеличиваться.
- [1] См.: Сегаран Т. Программируем коллективный разум. М.: Символ, 2015.