Классификация моделей данных

В качестве компонента гипертекстовой базы данных, описываемой на языке HTML, используется текстовый файл, который может легко передаваться, но сети с использованием протокола HTTP. Эта особенность, а также то, что HTML является открытым стандартом и огромное количество пользователей имеют возможность применять возможности этого языка для оформления своих документов, безусловно, повлияли на рост… Читать ещё >
Классификация моделей данных (реферат, курсовая, диплом, контрольная)
При работе с базами данных основными понятиями являются «данные» и «модель данных». Данные — это набор конкретных значений, параметров, характеризующих объект, условие, ситуацию или любые другие факторы [10]. Данные не обладают определенной структурой и становятся информацией тогда, когда пользователь задает им конкретную структуру, то есть вкладывает в них смысловое содержание.
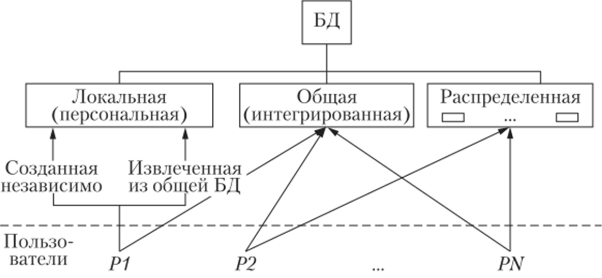
Рис. 1.5. Классификация БД, но характеру хранения данных и обращения к ним.
Модель данных — это некоторая абстракция, которая применительно к данным позволяет пользователям и разработчикам трактовать их уже как информацию, то есть сведения, содержащие не только данные, но и взаимосвязь между ними. Классификация моделей данных показана на рис. 1.6.
С учетом трехуровневой архитектуры баз данных (см. рис. 1.2) понятие модели данных трансформируется для каждого уровня. Например, физическая модель данных оперирует категориями, касающимися организации внешней памяти и структур хранения, используемых в данной операционной среде. В качестве физических моделей применяются различные методы размещения данных, основанные на файловых структурах и страничной организации данных.
Первостепенную важность имеют модели данных, используемые на концептуальном уровне. По отношению к ним внешние модели называются подсхемами и используют те же абстрактные категории, что и концептуальные модели данных.
При проектировании базы данных модель должна выражать информацию о предметной области в виде, независимом от используемой СУБД. Такая модель называется инфологической и отражает в естественной и удобной для разработчиков и других пользователей форме информационно-логический уровень абстрагирования, связанный с фиксацией и описанием объектов предметной области, их свойств и их взаимосвязей. Инфологические модели данных используются на ранних стадиях проектирования для описания структур данных в процессе разработки приложения, а даталогические модели уже поддерживаются конкретной СУБД.
Документальные модели данных соответствуют представлению о слабоструктурированной информации, ориентированной в основном на свободные форматы документов, текстов на естественном языке.
Модели, ориентированные на формат документа, связаны прежде всего со стандартным общим языком разметки — SGML, который был утвержден ISO в качестве стандарта еще в 1980;х гг. Этот язык предназначен для создания других языков разметки, он определяет допустимый набор дескрипторов, их атрибуты и внутреннюю структуру документа. С помощью SGML можно описывать структурированные данные, организовывать информацию, содержащуюся в документах, представлять эту информацию в некотором стандартизованном формате.
Гораздо более простой и удобный, чем SGML, язык HTML позволяет определять оформление элементов документа и вносить специальные дескрипторы в документы, при помощи которых осуществляется процесс разметки. Дескрипторы на языке HTML в первую очередь предназначены для управления процессом вывода содержимого документа на экране с помощью программы-клиента (например, браузера) и определяют этим самым способ представления документа, но не его структуру. На языке HTML документ представляется набором элементов, причем начало каждого элемента, а в большинстве случаев и его конец, отмечается дескриптором, который называется тегом. В начале элемента указывается открывающий тег, а в конце — закрывающий. Например, элемент, соответствующий размечаемому документу, открывается тегом, закрывается тегом и содержит внутри себя элементы заголовка и тела документа, ограниченные специальными тегами и :
заголовок документа.
тело документа.
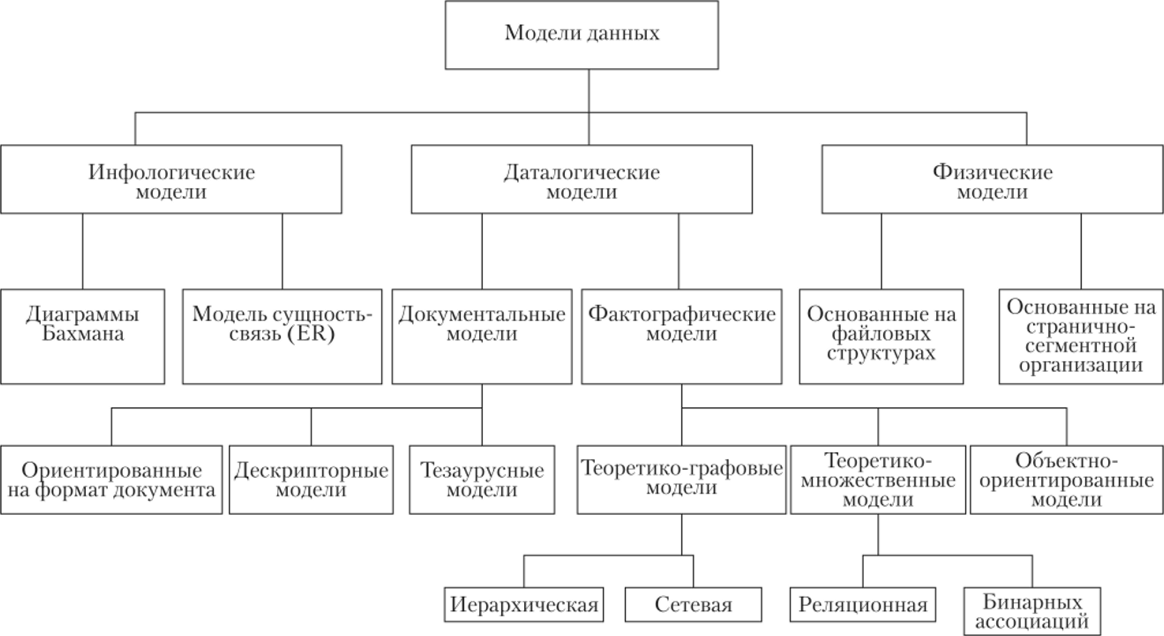
Рис. 1.6. Классификация моделей данных
В качестве компонента гипертекстовой базы данных, описываемой на языке HTML, используется текстовый файл, который может легко передаваться, но сети с использованием протокола HTTP. Эта особенность, а также то, что HTML является открытым стандартом и огромное количество пользователей имеют возможность применять возможности этого языка для оформления своих документов, безусловно, повлияли на рост популярности HTML и сделали его главным средством представления информации в Интернете.
Однако HTML сегодня уже не удовлетворяет в полной мере требованиям, предъявляемым современными разработчиками к языкам подобного рода. На смену ему пришел новый язык гипертекстовой разметки, мощный, гибкий и удобный язык XML.
XML — это расширяемый язык разметки, описывающий целый класс объектов данных, называемых XML-документами. Он используется в качестве средства для описания грамматики других языков и проверки правильности составления документов. Сам по себе XML не содержит никаких тегов, предназначенных для разметки, но определяет порядок их создания.
Тезаурусные модели основаны на принципе организации словарей, содержат определенные языковые конструкции и принципы их взаимодействия в заданной грамматике. Эти модели эффективно используются в системах-переводчиках, особенно многоязыковых переводчиках. Принцип хранения информации в этих системах и подчиняется тезаурусным моделям.
Дескрииторные модели — самые простые из документальных моделей, они широко использовались на ранних стадиях использования документальных баз данных. В этих моделях каждому документу соответствовал дескриптор — описатель. Этот дескриптор имел жесткую структуру и описывал документ в соответствии с характеристиками, требуемыми для работы с документами в документальной базе данных.
Иерархическая, сетевая и реляционная модели отражают способ установления связей между данными. Иерархическая и сетевая модели предполагают наличие связей между данными, имеющими какой-либо общий признак.
На рис. 1.7 условно изображено распределение учебных курсов Kl, К2, КЗ между преподавателями П1, П2, ПЗ. В ИМ связи между данными о преподавателях и читаемых ими курсах могут быть отражены в виде дерева, где возможны только односторонние связи от старших вершин к младшим (рис. 1.8). Это облегчает быстрый доступ к необходимой информации, но только если запросы учитывают структуру дерева. Например, оперативно можно определить, какие курсы читает преподаватель П2. Запросы, не учитывающие структуру дерева (например, какие преподаватели читают курс К1), выполняются медленнее.

Рис. 1.7. Распределение курсов между преподавателями

Рис. 1.8. Иерархическая модель данных
Указанный недостаток снят в СМ, где, по крайней мере теоретически, возможны связи «всех со всеми» (рис. 1.9). Использование ИМ и СМ ускоряет доступ к информации в БД. Но поскольку каждый элемент данных должен содержать ссылки на некоторые другие элементы, требуются значительные ресурсы как дисковой, так и основной памяти компьютера. Кроме того, для этих моделей характерна сложность реализации СУБД.
Реляционная модель является простейшей и наиболее привычной формой представления данных в виде таблицы (рис. 1.10). В теории множеств таблице соответствует термин «отношение» (relation), который и дал название реляционной.

Рис. 1.9. Сетевая модель данных
модели. Достоинством РМ является сравнительная простота инструментальных средств ее поддержки, а недостатком — жесткость структуры данных и зависимость скорости выполнения операций от размера таблиц.
При создании моделей данных используются такие понятия, как «сущности», «атрибуты» и «связи». Сущность — это отдельный класс объектов предметной области (сотрудники или клиенты, понятия или события), который должен быть представлен в базе данных. Атрибут — это свойство, описывающее определенный аспект объекта, значение которого следует зафиксировать в описании предметной области. Связь является ассоциативным отношением между сущностями, при котором каждый экземпляр одной сущности соединен с некоторым.

Рис. 1.10. Реляционная модель данных:
НП — номер преподавателя; НК — номер курса.
(в том числе нулевым) количеством экземпляров другой сущности. Объектно-ориентированная модель расширяет определение сущности с целью включения в него не только атрибутов, которые описывают состояние объекта, но и действий, которые с ним связаны, т. е. его поведение. В таком случае говорят, что объект инкапсулирует состояние и поведение.
В настоящее время наиболее распространенными являются системы управления базами данными, поддерживающие реляционную модель данных. Эти системы называются реляционными СУБД.