Формальные и неформальные языки.
Проблема формализации естественных языков

В качестве иллюстрации данного определения в указанном источнике приводится шутливый пример, в котором определяется овечий язык. Алфавит овечьего языка — это множество, состоящее всего из трех символов ?={б, е,!}. Все слова овечьего языка начинаются с символа «б», за которым следуют два или более символов «е» знак восклицания «!». Таким образом, цепочки «бее!», «бесе!» и даже «бееееее!» — овечьи… Читать ещё >
Формальные и неформальные языки. Проблема формализации естественных языков (реферат, курсовая, диплом, контрольная)
Формальными называются языки, лексико-грамматический строй которых допускает формальное, т. е. однозначное, точное и непротиворечивое описание. Для задания формального описания языка необходимо:
- • указать алфавит, т. е. множество используемых символов (букв) языка;
- • указать (перечислить) правила, но которым из этих символов будут строиться допустимые цепочки (строки, слова) языка.
Именно благодаря такому способу описания тексты на формальных языках доступны для машинного разбора. Цель машинного разбора зависит от того, что содержится в этих текстах — информация (данные) или программа (команды). В первом случае целью является извлечение информации, а во втором — исполнение программы.
Под программой здесь понимается последовательность команд, определяющих процедуру решения конкретной задачи компьютером (вычислительной машиной). Если программа написана на машинном языке, т. е. содержит набор низкоуровневых команд, понимаемых процессором компьютера, то она будет напрямую исполнена этим процессором. Иначе ей потребуется перевод (трансляция) с высокоуровневого языка программирования, на котором она написана, на низкоуровневый машинный язык. Такой перевод осуществляется с помощью специальной программы — транслятора (рис. 7.2).

Рис. 7.2. Трансляция программы.
Трансляторы бывают двух типов: компиляторы и интерпретаторы. Компиляторы транслируют программу на машинный язык сразу и целиком, создавая при этом машинно-исполняемый код. Интерпретаторы исполняют программу пошагово: берут одну инструкцию, транслируют ее, переходят к следующей инструкции и т. д. Разделение трансляторов на компиляторы и интерпретаторы условное: для любого компилируемого языка программирования можно реализовать интерпретатор, и наоборот.
Работа любого транслятора (компилятора) состоит из грех этапов (рис. 7.3).
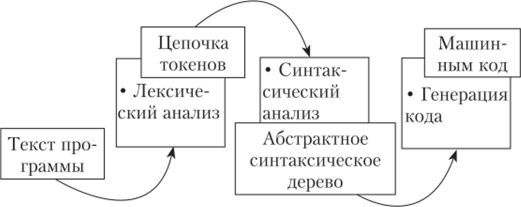
Рис. 73. Этапы работы компилятора.
На первом этапе выполняется лексический анализ, в ходе которого из текста программы последовательно считываются лексемы, или токены, — минимальные неделимые единицы языка. К таким неделимым единицам относятся слова, разделители, знаки алгебраических операций и т. д. Полученная цепочка токенов записывается компилятором в специальную таблицу, в которой для каждого токена указываются его код, тип (число, строка, оператор, идентификатор, разделитель и т. д.), некоторые другие характеристики.
На втором этапе выполняется синтаксический анализ, в ходе которого производится разбор полученной последовательности токенов. В результате разбора формируется абстрактное синтаксическое дерево, являющееся промежуточной и, как следует из названия, абстрактной формой представления программы. На рис. 7.4 представлено абстрактное синтаксическое дерево, полученное в результате разбора записи команды присваивания S = 2 • (п + 1). Внутренними вершинами этого дерева являются токены-операторы, а листьями — токены-операнды. Абстрактное синтаксическое дерево не является буквальным отражением кода, который оно представляет. Оно содержит только необходимые данные для записи операций. Например, можно заметить, что дерево на рис. 7.4 содержит все токены, кроме скобок. Скобки необходимы в текстовой записи команды, так как они определяют порядок операций, но в древовидной записи они избыточны, поскольку порядок операций уже определен самой структурой дерева.
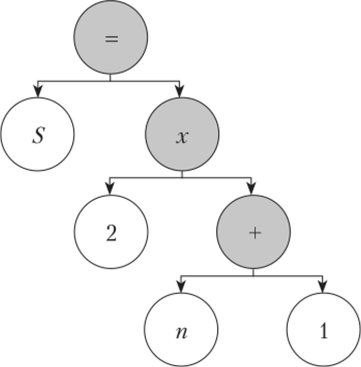
Рис. 7.4. Абстрактное синтаксическое дерево для команды.
На третьем этапе выполняется генерация машинного кода. Сначала абстрактное синтаксическое дерево преобразуется в линеаризованное абстрактное представление, например в трехадресный код, каждая команда которого состоит не более чем из трех операндов. Затем линеаризованное представление переводится в машинный код.
Опишем порядок построения дерева, представленного на рис. 7.4. Построение ведется сверху вниз. В качестве вершины выбирается оператор, выполняющийся последним. Это «=». Его левой ветвью является операнд «S», а правой ветвью — выражение 2 • (п + 1). Построение левой ветви завершено, так как «5» — неделимый токен. Построение правой ветви, в свою очередь, повторяет процедуру разбора, т. е. снова выбирается оператор, выполняющийся последним. Это «х». Его левой ветвью является операнд «2», правой ветвью — выражение (п + 1). Построение левой ветви завершено, поскольку «2» — неделимый токен. Построение правой ветви снова повторяет процедуру разбора, т. е. снова выбирается оператор, выполняющийся последним. Это «+». Его левой ветвыо является операнд «п», правой ветвью — операнд «1». Построение дерева завершено, так как оба операнда — неделимые токены.
Программа считается понятой компьютером, если без ошибок переведена на машинный язык. Для этого она (программа) должна быть написана на формальном языке, т. е. языке, который может быть переведен на машинный язык. Обобщая, можно сказать, что смысл любого текста считается понятым, если этот текст переведен на другой язык, известный компьютеру или оператору1.
Известно и другое, более строгое определение формального языка, которое используется преимущественно в таких дисциплинах, как математическая логика, теория алгоритмов, теория формальных грамматик и языков, теория автоматов. Согласно этому определению формальным языком называется множество конечных строк (цепочек символов, слов) над конечным алфавитом[1][2].
В качестве иллюстрации данного определения в указанном источнике приводится шутливый пример, в котором определяется овечий язык. Алфавит овечьего языка — это множество, состоящее всего из трех символов ?={б,е,!}. Все слова овечьего языка начинаются с символа «б», за которым следуют два или более символов «е» знак восклицания «!». Таким образом, цепочки «бее!», «бесе!» и даже «бееееее!» — овечьи слова, а цепочки «бе!» и «бебе!» — не овечьи. Согласно этому определению, овечий язык — формальный, поскольку представляет собой бесконечное множество L = {бее!, беее!, бееее!, беееее!, бееееее!}, состоящее из конечных строк над конечным алфавитом Х={б, е,!}.
Приведенный овечий язык невозможно описать простым перечислением входящих в него слов, так как этих слов бесконечное количество. Для описания такого языка предназначена формальная грамматика — конечный набор правил, задающих множество корректных цепочек языка на основе символов его алфавита. Различают два типа формальных грамматик: порождающие (синтезирующие) и распознающие (анализирующие). Первые описывают правила, позволяющие порождать корректные цепочки языка, а вторые описывают правила, позволяющие распознавать эти цепочки.
Роль распознающей грамматики может выполнять конечный распознающий автомат. Автомат последовательно читает по символу из входной цепочки, каждый символ переводит автомат из одного состояния в другое в соответствии с функцией переходов. У автомата есть начальное и конечное состояния. Если при чтении цепочки символов автомат переходит в конечное состояние, то говорят, что он допускает (распознает) эту цепочку как корректную. Корректными, или допустимыми, называются цепочки, чтение которых переводит автомат из начального состояния в конечное.
На рис. 7.5 представлен конечный распознающий автомат для овечьего языка. Входная стрелка указывает, что начальным состоянием является 1. Дуга с меткой «б», ведущая из 1 в 2, означает, что если будет считан символ «б», то автомат перейдет в состояние 2. Дуга с меткой «е», ведущая из 2 в 3, означает, что если будет считан символ «е», то автомат перейдет в состояние.
3. Аналогично, дуга с меткой «е», ведущая из 3 в 4, означает, что если будет считан символ «е», то автомат перейдет в состояние 4. В состоянии 4 автомат допускает любое число повторов символа «е» и один символ «!», после считывания которого автомат переходит в заключительное состояние 5.

Рис. 7.5. Конечный автомат для распознавания овечьего языка Цель следующего примера — продемонстрировать эффективность использования конечных преобразующих автоматов при решении задач обработки текстов на формальном языке. Автором примера является Л. Шень[3]
В тексте возведение в степень обозначалось двумя идущими подряд звездочками. Решено заменить это обозначение на «А» (так что, к примеру, «х**у» заменится на «х^у»). Как это проще всего сделать? Исходный текст разрешается читать символ за символом, получающийся текст требуется печатать символ за символом.
Решение. Построим таблицу переходов для конечного автомата, реализующего такую замену (табл. 7.1). Под таблицей переходов понимается таблица, строки которой соответствуют состояниям автомата, а столбцами — символы автоматного языка. В ячейках таблицы записываются состояния, в которые переходит автомат из состояний, записанных в соответствующих строках, при прочтении символов, записанных в соответствующих столбцах. Можно выделить два состояния автомата:
- 1 — основное состояние;
- 2 — состояние после прочтения «*».
Таблица 7.1
Таблица переходов конечного автомата, преобразующего.
«**» в «Л».
Исходное состояние. | Очередной символ. | Новое состояние. | Действие. |
*. | —. | ||
Любой, кроме *. | Вывести символ. | ||
*. | Вывести л | ||
Любой, кроме *. | Вывести * и символ. |
После того как таблица переходов построена, не представляет сложности нарисовать конечный автомат (рис. 7.6).
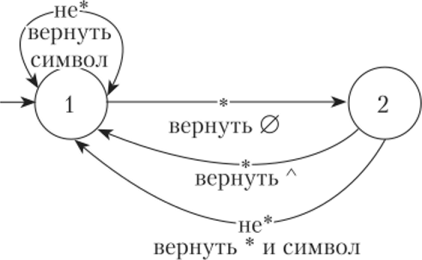
Рис. 7.6. Конечный автомат-преобразователь (преобразует «**» в «Л»).
Конечные автоматы-преобразователи используются не только при обработке текстов на формальных языках. В обработке текстов на естественных языках часто возникает задача нечеткого поиска, решение которой построено на использовании автомата Левенштейна, принимающего некоторое слово тогда и только тогда, когда расстояние между ним и заданным словом не превышает некоторой величины. Задачу нечеткого поиска иначе можно сформулировать следующим образом: по заданному слову найти в словаре множество слов таких, что расстояние Левенштейна между этими словами и заданным словом не превышает какого-то целого числа.
Расстоянием Левенштейна между двумя словами называется минимальное количество элементарных операций, которое нужно совершить, чтобы из одного слова получить другое. Под элементарными операциями понимаются операция вставки одного символа, операция удаления одного символа и операция замены одного символа па другой. Расстояние Левенштейна может использоваться для исправления опечаток и ошибок при вводе текста, для поиска объектов по неточным названиям, для исправления ошибок, допущенных при автоматическом распознавании речи или сканировании текста.
К примеру, расстояние Левенштейна между словами «кошка» и «собака» равно 3. Сначала выполняется операция вставки символа, затем 2 операции замены символа.
- 1. КОШКА -> КОШАКА.
- 2. КОШАКА ^ КОБАКА.
- 3. КОБАКА ^ СОБАКА.
Редакционным предписанием называется последовательность операций, необходимых для получения второго слова из первого кратчайшим способом. Для нахождения редакционного предписания строится матрица Левенштейна. Первоначально она выглядит следующим образом (табл. 7.2).
Таблица 7.2
Исходное состояние матрицы Левенштейна.
С. | О. | Б. | А. | К. | А. | ||
К. | |||||||
о. | |||||||
ш. | |||||||
к. | |||||||
А. |
Заполнение ячеек матрицы происходит слева направо и сверху вниз по правилу.
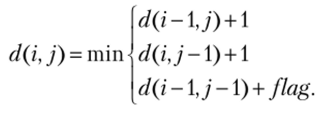
Если буква в текущей i-й строке совпадает с буквой в текущем j-м столбце, то flag равен 0, иначе 1. Таким образом, чтобы вычислить значение некоторой ячейки, нужно знать значения ее соседей слева, сверху, и слева-сверху, т. е. но диагонали (табл. 7.3). После всех вычислений расстояние Левенштейна можно увидеть в последней ячейке матрицы.
Таблица 73
Состояние матрицы Левенштейна после всех вычислений.
С. | О. | Б. | А. | К. | А. | ||
К. | |||||||
о. | |||||||
ш. | |||||||
к. | |||||||
А. |
Практически все искусственные языки формальны, т. е. могут быть заданы либо простым перечислением цепочек символов, либо с помощью формальной грамматики. Наиболее яркими примерами формальных искусственных языков являются, как вы уже заметили, любые языки программирования и любые машинные языки.
В отличие от искусственных языков, все естественные языки неформальны, а попытки их формализации, т. е. представления в виде строгих и точных описаний, доступных машинному пониманию, порождают известную проблему размерности. Эта проблема, также известная как проклятие размерности (curse of dimensionality), очень часто возникает при моделировании сложных систем, для которых характерно огромное число вариантов описываемых состояний и связей. Ее следствиями являются предельная трудоемкость описания и обработки данных и неконтролируемый рост числа коллизий.
Приведем цитату, которая, на наш взгляд, очень точно раскрывает суть изложенной проблемы: «Казалось, достаточно чуть детальнее, чем в школьном учебнике, описать правила языка, перевести их на язык алгоритмов — и компьютер начнет понимать наши тексты. Но человеческий язык оказался невероятно сложен. То, что в речи нам кажется элементарным и само собой разумеющимся, при попытке формализовать и алгоритмизировать превращается в огромный свод правил и исключений, делающих задачу моделирования языка предельно сложной. Применение нескольких правил приводило к взаимоисключающим результатам»1.
Сложность (а может, и невозможность) полной и окончательной формализации естественного языка, тем не менее, не означает невозможности его машинной обработки. Она лишь заставляет компьютерную науку искать прагматические подходы к решению задач обработки естественного языка. Другими словами, невозможность построения универсальной лингвистической модели языка заставляет исследователей и разработчиков обратиться к созданию и использованию упрощенных, прагматических моделей.
Зарождение прагматизма как общенаучного подхода связывают с именем американского философа Ч. Пирса, утверждавшего, что целью исследования является «устранение сомнения, мешающего успешным действиям»[4][5]. Другой американский философ Дж. Дыои развил эти идеи, утверждая, что опыт — это руководящая сила в науке, опыт основан па ожидании и предвидении, а гипотеза, которая работает, и есть истинная[6]. Таким образом, прагматизм основывается на двух принципах:
- • принцип достаточности — гипотеза, которая работает, истинна;
- • принцип ожидаемое™ — основой опыта служат ожидание и предвидение.
Под ирагматически-ориентированной моделью естественного языка понимается такое его формализованное описание, которое строится исходя из конкретных целей моделирования и основывается на указанных выше принципах достаточности и ожидаемое™[7]. Соблюдение этих принципов означает, что описание языка реализуется с помощью минимально достаточного набора средств (принцип достаточности), но с максимально возможной интеллектуальностью, основанной на практическом опыте, т. е. предвидении или ожидании определенного языкового контекста (принцип ожидаемости). Считается, что использование прагматически-ориентированных моделей позволит избежать традиционных проблем формализации естественного языка и минимизировать усилия, необходимые для создания реальных систем обработки естественного языка1.
К числу простейших прагматико-ориентированных моделей естественного языка можно отнести модель Bag-of-words[8][9]. Эта модель представляет любой текст как набор входящих в него слов без учета их порядка и связей, так что смысл текста определяется только по ключевым словам (рис. 7.7). Отсюда, кстати, следует способ определения семантической близости двух текстов — на основе совпадения ключевых слов (на этом базовом принципе также основан информационный поиск по ключевым словам).
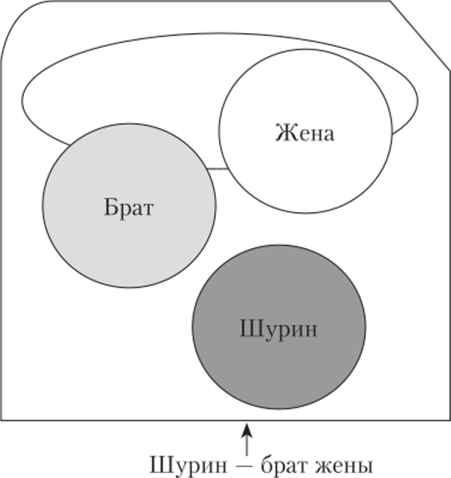
Рис. 7.7. Пример представления текста в модели Bag-of-words
Простота модели Bag-of-words является одновременно ее достоинством и недостатком. С одной стороны, игнорирование порядка слов упрощает процесс обработки текстов: тексты просто разбиваются на слова, а полученные слова нормализуются (приводятся к словарным формам). С другой стороны, в некоторых случаях игнорирование порядка слов может привести к частичной или полной потере смысла.
Чтобы пояснить, как может произойти такая потеря, немного утрируем рассматриваемый подход. С этой целью представим в виде набора слов словосочетания «жена брата» и «брат жены». После отбрасывания связей и нормализации слов эти словосочетания оказываются тождественными, так как описываются одинаковыми наборами {брат, жена}, хотя на деле выражают совершенно разные понятия. Частично эту проблему решает включение в наборы слов не только однословных терминов, но и словосочетаний.
Тем не менее достоинства прагматико-ориентированных моделей с лихвой компенсируют их недостатки, особенно если сравнивать эти дешевые и легкие модели с дорогими и тяжеловесными универсальными моделями языка.
Говоря о дороговизне универсальных моделей, мы имеем в виду то, что качество этих моделей напрямую зависит от наличия лингвистических ресурсов (словарей, тезаурусов, аннотированных корпусов и т. д.). Поскольку подобные ресурсы создаются и размечаются вручную, в течение многих лет, усилиями больших авторских коллективов, то они редко бывают полностью открытыми и бесплатными. Говоря о тяжеловесности универсальных моделей, мы подразумеваем уже обозначенную проблему размерности, в силу которой эти модели являются сложными в проектировании и применении.
По поводу сложностей использования универсальных лингвистических моделей в системах обработки естественного языка даже существует шутка: «Всякий раз, когда лингвист покидает коллектив, качество распознавания повышается»[10]. Под распознаванием здесь понимается сложный технологический процесс обработки естественного языка, состоящий из множества этапов.
- [1] См.: Reghizzi S. С., Breveglieri L, Morzent A. Formal Languages and Compilation. London: Springer, 2009.
- [2] Cm. Jurafsky D., MattinJ. II. Speech & Language Processing. Gurgaon: PearsonEducation India, 2000.
- [3] Приводится по: Шень Л. Программирование: теоремы и задачи. М.: Изд-воМЦНМО, 2004.
- [4] Сараев В. До машины наконец дошло // Эксперт. 2014. № 16.
- [5] См.: Peirce С. S. How to make our ideas clear // The Nature of Truth: Classic andContemporary Perspectives / ed. by M. Lynch. Cambridge: MIT Press, 2001.
- [6] Cm.: Dewey J. Logic: The theory of inquiry (1938) // Idem. The Later Works, 1925—1953. Carbondale; Edwardsville: Southern Illinois University Press, 1981 —1990. Vol. 12.
- [7] Сулейманов Д. IJJ. Двухуровневый лингвистический процессор ответных текстов па естественном языке // Сборник трудов Международной научно-технической конференции OSTIS-2011. Минск, 2011.
- [8] См.: Сулейманов Д. Ш. Двухуровневый лингвистический процессор…; Шереметьева С. 0., Дюмин И. Ю. Об экономии усилий при разработке многоязычныхлингвистических е-ресурсов // Вестник Южпо-Уральского государственного университета. Серия: Лингвистика. 2012. № 25.
- [9] Manning С. D., Raghavan Р., Schutze II. Introduction to Information Retrieval. Cambridge: Cambridge University Press, 2008. T. 1. P. 496.
- [10] «Anytime a linguist leaves the group the recognition rate goes up» (приводитсяno: Quast //., Bosch R. Speech Dialogue Systems and Natural Language Processing //Computer Speech. Berlin: Springer Berlin Heidelberg, 2004).